cuda #gpu
实验目的
熟悉Llama 3.2 大语言模型的算法原理,掌握在DLP 平台上移植优化聊天机器人的 方法和流程;能够使用LoRA 对Llama3.2 模型进行微调;能够使用Triton 语言进行Flash Attention 算子的封装并对Llama3.2 模型进行算子优化,具体包括:
- 掌握Llama 系列模型的基本原理,特别是基于大型语言模型Llama 3.2 构建聊天机器人的基本概念和操作步骤,深入理解其在对话生成、多模态生成中的应用;
- 了解轻量化微调技术的关键概念,包括LoRA 轻量化微调等基本原理,掌握使用SWIFT 轻量化训练推理工具进行LoRA 微调的基本方法;
- 能够在DLP 平台上部署Llama3.2 模型,实现人机快速聊天应用并实现轻量化微调。
- 了解Triton 语言进行Flash Attention 算法实现的基本原理、算法流程;
- 能够使用Flash Attention 算子对Llama3.2 模型进行优化。
1、# 进入 /opt/code_chap_8_opt_student/ 目录
cd /opt/code_chap_8_opt_student/
#进行环境激活
source env.sh
2、补全 infer-3b.py、infer_speed_test.py、infer-11b.py,完成原生 Llama3.2 系统构建;
#进入目录
cd llama3.2
#运行原生Llama3.2模型的文本生成
python infer-3b.py
#文本推理速度测试
python infer_speed_test.py
#运行原生Llama3.2模型的多模态生成
python infer-11b.py
3、补全finetune_math.sh、finetune_ruozhiba.sh、finetune_latexocr.sh、infer_math.sh 、 infer_ruozhiba.sh、infer_latexocr.sh 文件完成基于 Llama3.2模型的 LoRA 微调与推理。
# 基于blossom-math-v2的LoRA微调
bash finetune_math.sh
# 基于弱智吧的LoRA微调
bash finetune_ruozhiba.sh
# 基于latex-ocr-print的LoRA微调
bash finetune_latexocr.sh
# 基于blossom-math-v2的LoRA推理
bash infer_math.sh
# 基于弱智吧的LoRA推理
bash infer_ruozhiba.sh
# 基于latex-ocr-print的LoRA推理
bash infer_latexocr.sh
4、完成基于寒武纪 Triton 的 Flash attention 算子封装,补全 llama3.2/flash_attention_triton_opt.py 文件,构建起前向传播模块、 反向传播模块、高效注意力机制模块,并完成单算子测试。
#进入目录
cd llama3.2
#完成算子封装并进行单算子测试
python flash_attention_triton_opt.py
5、完成 llama3.2 模型中 Flash Attention 算子的替换,修改/opt/tools/nativate/transformers_mlu/src/transformers/models/mllama/modeling_mllama.py文件。
6、再次运行 Llama3.2的系统构建及推理测试程序,验证在 DLP 平台上替换 Flash Attention算子后 Llama3.2的正确性,并进行基于LoRA的微调和推理;
#进入目录
cd llama3.2
#运行原生Llama3.2模型的文本生成
python infer-3b.py
#文本推理速度测试
python infer_speed_test.py
#运行原生Llama3.2模型的多模态生成
python infer-11b.py
# 基于blossom-math-v2的LoRA微调
bash finetune_math.sh
# 基于弱智吧的LoRA微调
bash finetune_ruozhiba.sh
# 基于latex-ocr-print的LoRA微调
bash finetune_latexocr.sh
# 基于blossom-math-v2的LoRA推理
bash infer_math.sh
# 基于弱智吧的LoRA推理
bash infer_ruozhiba.sh
# 基于latex-ocr-print的LoRA推理
bash infer_latexocr.sh
infer_speed_test.py
import transformers
import torch
import torch_mlu
import time
model_id = "/workspace/model/favorite/large-scale-models/model-v1/Llama-3.2-3B/"
# ✅ 创建文本生成的 pipeline,指定任务类型、模型路径、数据类型,并在 MLU 上运行
pipeline = transformers.pipeline(
task="text-generation",
model=model_id,
device=torch.mlu.current_device(),
torch_dtype=torch.float16
)
messages = [
{"role": "system", "content": "You are a story writing chatbot"},
{"role": "user", "content": "Once upon a time, .... start to write a very long story"},
]
# ✅ 应用聊天模板,将消息转化为 prompt(以下假设模型使用 ChatML 或类似格式)
prompt = "<|system|>\nYou are a story writing chatbot\n<|user|>\nOnce upon a time, .... start to write a very long story\n<|assistant|>\n"
# ✅ 终止符号:通常为模型的 `eos_token_id`,加上自定义终止 token ID(如 <|eot_id|>)
# 为了通用,这里取 tokenizer.eos_token_id,如果知道 <|eot_id|> 的 ID,可加入
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
terminators = [tokenizer.eos_token_id] # 可添加额外自定义 terminator id
times = []
for i in range(1):
max_length = 256
# ✅ 记录开始时间
start_time = time.time()
# ✅ 执行推理
outputs = pipeline(
prompt,
max_new_tokens=max_length,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
# ✅ 记录结束时间
end_time = time.time()
# ✅ 计算耗时
elapsed_time = end_time - start_time
# ✅ 计算吞吐量(tokens/s)
tokens_per_sec = max_length / elapsed_time
# ✅ 存入列表
times.append(tokens_per_sec)
print(f"iter: {i}, Tokens per second: {tokens_per_sec:.2f}")
print("========================")
# ✅ 计算平均吞吐量
print("Average tokens per second:", sum(times) / len(times))
print("========================")
print("INFERSPEED PASS!")infer-11b.py
import requests
import torch
import torch_mlu
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "/workspace/model/favorite/large-scale-models/model-v1/Llama-3.2-11B-Vision-Instruct/"
# ✅ 加载条件生成模型,指定模型路径、数据类型和MLU设备
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
).to("mlu")
# ✅ 从预训练模型加载处理器
processor = AutoProcessor.from_pretrained(model_id)
# ✅ 打开本地图像文件
image = Image.open("your_image.jpg") # <-- 请替换为实际图像路径
# ✅ 定义用户消息,包含图片和文本
messages = [
{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
# ✅ 应用聊天模板(如支持 ChatML 格式)
input_text = processor.apply_chat_template(messages, tokenize=False)
# ✅ 处理图像和文本输入
inputs = processor(
text=input_text,
images=image,
return_tensors="pt"
).to("mlu")
# ✅ 使用模型生成文本
output = model.generate(**inputs, max_new_tokens=64)
# ✅ 解码输出
generated_text = processor.tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
print("Llama3.2 multimodalchat PASS!")要搞清楚 Q,K,V 的 stride,offset 等参数是干什么的。还是得明白 triton 最终对应到 CUDA 中也就是 GPU 编程模型中的什么。
CUDA 快速入门
https://enzo-miman.github.io/#/README
其中包含: 1、《Enzo|CV深度学习课件》课件
- 可作为学习资料,也可作为随时翻阅的速查手册
- 课件为线上飞书课件(网页),我会持续更新,你亦可查看购买之后更新的所有的内容
- 部分章节有 讲解视频,以百度云链接的形式(或b站视频链接形式) 贴在对应页面置顶处
- 当前深度学习基础内容已基本更新完(2024.3.17),后续会轻度迭代,开始重点更新经典算法相关内容
- 随着课件完善,后续会逐步涨价
2、除深度学习基础内容外,课件中还包括 :
- transformer 与 DETR 系列视频中的课件
- 部分充电视频课程,包括 DETR 代码精讲、positional encoding、知识蒸馏,等
- 不包括!!不包括 RT-DETR 和 DDPM 的充电视频课程,需单独购买 !!
3、包括其他深度学习相关资料
虽然说这个付费内容,但是整理的确实很全。
CUDA 编程指北:从入门到实践 - 离心的文章 - 知乎 https://zhuanlan.zhihu.com/p/680075822
人大图灵班大佬的文章,很不错。
Medium 上的一篇文章,优点是有很多易于理解的示意图便于领会编程模型架构 https://0mean1sigma.com/what-is-gpgpu-programming/
非常好的问题!在 CUDA 中,处理并行线程的边界情况时,取整和索引边界控制是非常关键的,稍有不慎就可能导致 越界访问(out-of-bounds) 或 计算错误。我们来系统介绍一下。
GPU 的编程模型架构
关键词:分级别的存储架构,
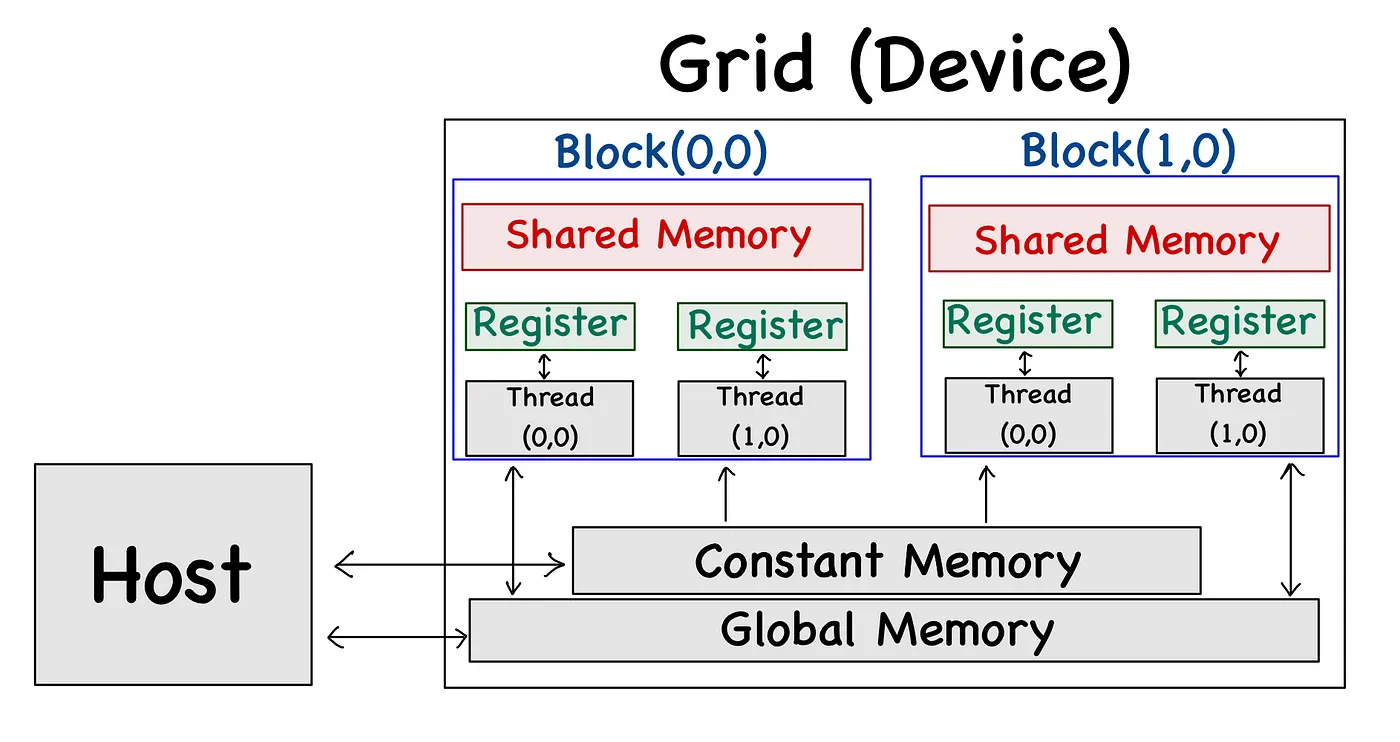
美国公开课的优点,其实也不是完全公开,比如说我看的并行计算课中的 slides 都会提 GPU,然后大模型课也会讲 GPU 架构但都是一带而过,非常宽泛,非常有我本科那些云里雾里专业课的风范,到头来还是得自己去多方查询,才能真能理解清楚的东西。不过美国公开课的优点是大多代码开源,已经很伟大了。如果事无巨细,也不能培养学生自主学习的能力了。(算是一种平衡点)
✅ CUDA 中常见的取整和边界相关情况
1. 线程索引计算(Thread Indexing)
CUDA 中每个线程块有多个线程,每个线程要确定自己负责计算哪一部分数据,通常写法如下:
int idx = blockIdx.x * blockDim.x + threadIdx.x;但问题来了:当数据数量不是 block 数 × 每块线程数的整数倍时,会出现“空线程”或“越界线程”。
2. 处理边界时的典型判断:
if (idx < N) {
// 安全访问数组
output[idx] = input[idx] * 2;
}✅ 上面这句 if (idx < N) 是 CUDA 编程中必须掌握的技巧,防止线程访问超出数组范围。
3. 如何确定启动线程总数
如果你有 N 个数据元素,每个线程处理一个,你可能会写:
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize; // ⬅️ 向上取整这就是在 CUDA 中最常见的「向上取整除法」,用于保证即使 N 不是 blockSize 的整数倍,最后一块也能处理剩余的数据。
📌 公式说明:
numBlocks = ceil(N / blockSize)
= (N + blockSize - 1) // blockSize ⬅️ Python/CUDA通用技巧4. Grid/Block 中二维情况的边界控制
在二维网格(如矩阵)操作时,也要分别检查 x 和 y 的边界:
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
output[y * width + x] = ...;
}🔄 总结
| 场景 | 说明 | 示例 |
|---|---|---|
| 向上取整 | 保证分块能覆盖所有元素 | (N + blockSize - 1) / blockSize |
| 向下取整(默认) | 对齐块索引时使用 // | idx = (x // TILE_SIZE) |
| 边界判断 | 防止越界访问 | if (idx < N) |
| 多维边界 | 需要同时判断 x 和 y | if (x < W && y < H) |
部署大模型平台(可以体验一下多卡部署,跑一跑框架估计也就花个几块钱)
当然了,初学者用 colab 就很够了(16 G 显存,不用折腾环境)
我的现有观感
GPU 编程的核心就是从 CPU 使用的内存中搬运数据到 GPU 使用的各种内存中,同时利用好 GPU 拥有的大量计算核心这一优势。
Triton
Triton 把 CUDA 中 threads 这一级别的分配自动完成了,用户只需要参与 block 级别的分配。