Chipgpt, autosilicon, date is all you need,large
Chipgpt
ChipGPT: How far are we from natural language hardware design
一、问题背景
NOTE
在这篇文章提出的时间点大模型在 Verilog 生成领域面临模糊的输入/输出集成、缺乏关于功耗、性能和面积(PPA)指标的硬件特定知识,以及在生成复杂、分层设计方面的挑战。ChipGPT 通过一个系统化的四阶段框架解决了这些限制,该框架利用了现有 LLM,无需进行修改或再训练。
二、核心方法论:一套围绕LLM的“四段式”工程框架
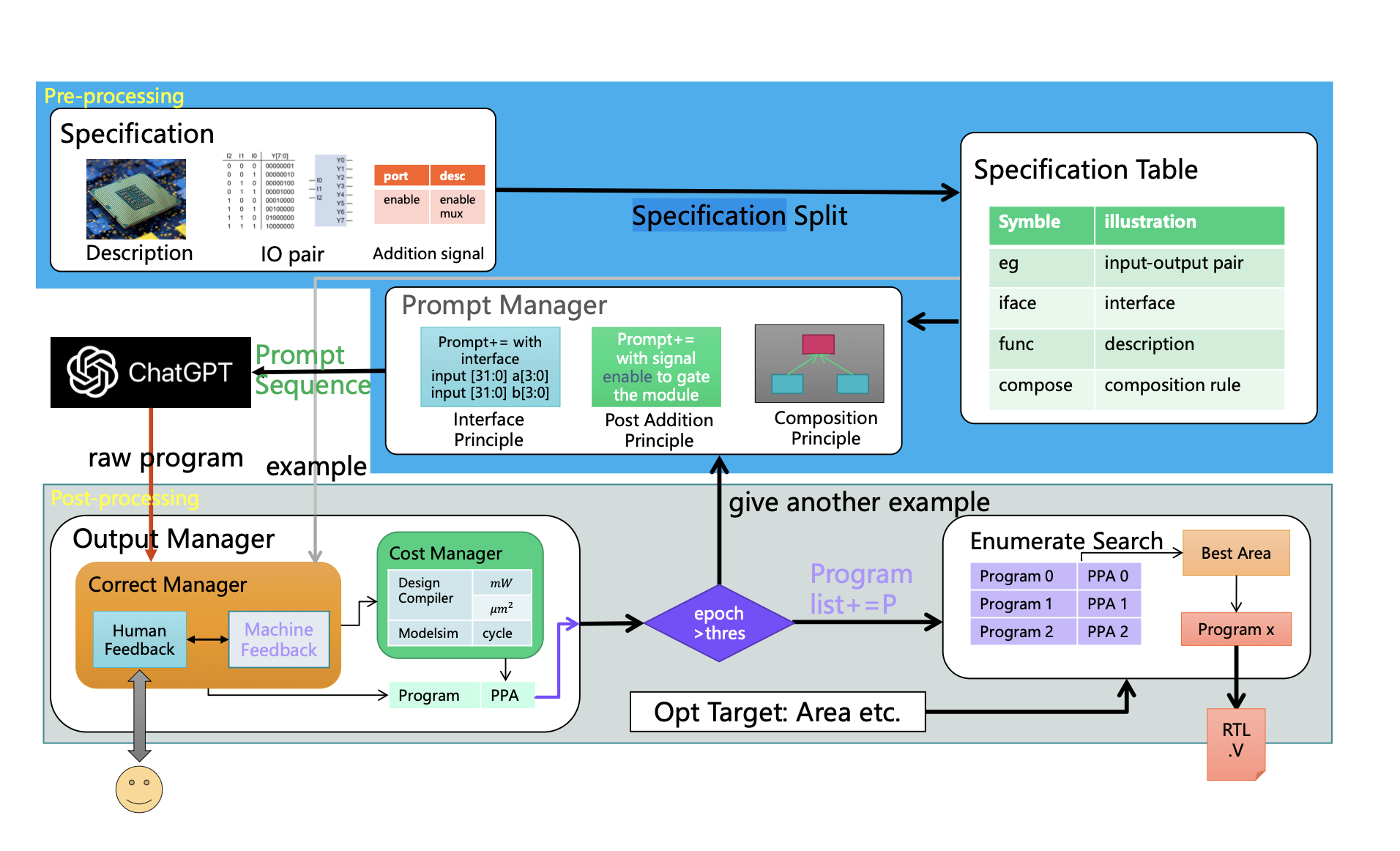 ChipGPT 框架图
ChipGPT 框架图
论文的精髓在于其首次提出的ChipGPT框架,它并非一个新的模型,而是一套精巧的、无需微调或重新训练LLM的“工作流”。这个框架通过前置和后置处理,巧妙地“引导”和“修正”通用LLM的行为,克服了硬件设计中面积/功耗/性能的困难,并且也是首个提出评估大模型从自然语言到硬件描述语言能力的研究。(三维预测空间,健壮性,完整性,描述能力)
预处理(Pre-processing):这是整个框架的智慧所在,旨在将模糊的自然语言需求转化为LLM可以理解的、结构化的提示(Prompt)。
规格拆分:首先,将用户的自然语言描述拆分为四个关键部分:iface(接口定义)、func(功能描述)、compose(模块组合规则)和eg(用于后续验证的输入输出样例)。这一步实现了从非结构化到半结构化的转换。
提示管理器(Prompt Manager):这是引导LLM生成高质量代码的核心。
-
作者基于实验总结出三大原则:
-
接口原则:在提示中明确、完整地定义模块的输入输出接口。这极大地稳定了LLM的输出,确保了生成模块的可集成性。
-
后追加原则:对于复杂的功能(如ready-valid握手信号),先让LLM生成核心功能的代码,再通过一个后续的提示让它“追加”握手逻辑。这种分步引导的方式避免了LLM因任务过载而产生错误。
-
模块组合原则:采用“由底向上”的策略。先让LLM生成所有底层的子模块,然后在生成顶层模块的提示中,将已生成的子模块接口信息作为上下文提供给LLM,引导它正确地完成模块的实例化和连接。
-
LLM生成(LLM Generation):将经过精心设计的提示输入到GPT-3.5等模型中,生成“原始”的Verilog代码。
后处理(Post-processing):这是确保最终设计质量和实现优化的关键环节。
输出管理器(Output Manager):首先,通过编译器和仿真器进行“机器反馈”,自动修正语法和简单的逻辑错误。对于无法自动修复的问题,再引入“人工反馈”进行修正。
成本管理器(Cost Manager):将修正后的代码输入到专业的EDA工具(如Synopsys Design Compiler)中进行综合,从而获取真实的PPA数据。
枚举搜索(Enumerative Search):LLM的输出具有随机性,ChipGPT利用这一点,让模型针对同一需求生成多个不同的设计版本。然后,通过枚举搜索,比较所有有效版本的PPA数据,并根据用户的优化目标(如最小面积或最低功耗)选择最终的最佳设计。
三、主要结果与贡献:量化证明框架的有效性
论文通过一系列实验,清晰地展示了ChipGPT框架的显著优势:
极大地提升了可编程性和效率:与传统的敏捷开发方法相比,ChipGPT将设计人员需要编写的代码量减少了数倍(相比HLS减少9.25倍,相比Chisel减少5.32倍)。这意味着开发效率的巨大飞跃。 显著改善了代码质量:通过结构化的提示工程,ChipGPT生成的代码正确性远高于直接使用ChatGPT。与基线相比,代码质量(错误行数)平均提升了2.01倍。
实现了PPA优化:这是最令人印象深刻的贡献。该框架成功地将LLM与EDA工具链结合,对于复杂设计,在面向面积优化时,平均能将电路面积减少47%(同 LLM 生成的代码相比)。这证明了ChipGPT不仅能“做对”,还能“做好”。
展示了高度的实用性:该框架无需对大模型本身进行昂贵的微调,而是通过API调用和外部工具集成的方式工作,使其具有很强的可部署性和通用性。
Autosilicon
AutoSilicon 使 LLM 能够自主地将大规模、复杂的代码设计任务分解为更简单、更小的任务,从而扩展了基于 LLM 的 HDL 代码设计的能力范围。为了进一步提升硬件设计的质量,我们将编译器和仿真器集成到 AutoSilicon 框架中,使 LLM 能够自主地与其交互、评估并优化其生成的代码。此外,我们还提出了包括投票策略和记忆机制在内的多种策略,以提升 LLM 的设计质量和效率。
该系统能够:
- 将大规模、复杂的代码设计任务分解为更小、更简单的子任务;
- 提供一个编译和仿真环境,让 LLM 能够编译和测试自己生成的每一段代码;以及
- 引入一系列优化策略。
问题陈述
框架
智能体使用 JSON 模板(如下表)来规划输出,任务调度器解析该 JSON 按顺序逐一调用智能体去完成各个子任务,从而实现了复杂任务的有序分解
表 2:实现模块的设计规范的关键字段及其对应条目
| 字段 (Fields) | 条目 (Entry) | 描述 (Description) |
|---|---|---|
| 模块描述 (Module Description) | Name (名称) | 当前模块的名称。 |
| Overview (概述) | 当前模块实现的关键设计要求和概述。 | |
| Design Details (设计细节) | 当前模块的架构细节。 | |
| 时钟/复位 (Clock/Reset) | Clock Freq (时钟频率) | 时钟频率。 |
| Reset Polarity (复位极性) | 复位当前模块时,复位信号的极性(例如高电平有效或低电平有效)。 | |
| 有限状态机 (Finite State Machines) | States (状态) | 所有的状态及其对应的描述。 |
| State Transition Edges (状态转换边) | 状态转换图中的所有边及其对应的转换条件。 | |
| I/O 规范 (I/O Specification) | Control Signal List (控制信号列表) | 模块 I/O 信号中的所有控制信号。 |
| Data Signal List (数据信号列表) | 模块 I/O 信号中的所有数据信号。 | |
| Control Signal Encoding (控制信号编码) | 所有控制信号的可能取值及其各自的含义。 | |
| Input Signals (输入信号) | 当前模块 I/O 中所有输入信号的名称/位宽/描述。 | |
| Output Signals (输出信号) | 当前模块 I/O 中所有输出信号的名称/位宽/描述。 | |
| 测试策略 (Testing Strategy) | Testing Strategy (测试策略) | 用于评估当前模块的测试策略和测试向量。 |
举例说明:设计一个 RISC-V CPU 让我们用一个具体的例子来走一遍流程:
初始状态: 任务队列里只有一个任务:
{id: 0, name: ‘RISC-V_CPU’, status: PENDING, deps: [], spec: ‘用户输入的原始描述’} 第一次调度: 调度器发现任务 0 没有依赖,于是分派给设计智能体。
任务分解: 设计智能体判断 RISC-V_CPU 过于复杂,返回一个 JSON 分解计划,其中定义了 ALU, RegFile, Fetch_Unit 等模块,并指明 Fetch_Unit 依赖 ALU 等关系。
动态重调度: 任务调度器解析 JSON,任务队列变为:
{id: 0, name: 'RISC-V_CPU', status: PENDING, deps: [1, 2, 3, ...], ...}
{id: 1, name: 'ALU', status: PENDING, deps: [], spec: '从 JSON 中提取的 ALU 规范'}
{id: 2, name: 'RegFile', status: PENDING, deps: [], spec: '...'}
{id: 3, name: 'Fetch_Unit', status: PENDING, deps: [1, ...], spec: '...'}
... (其他子模块)
自底向上执行: 在下一轮循环中,调度器发现 ALU (id: 1) 和 RegFile (id: 2) 的依赖列表为空,于是将它们分派出去。而 Fetch_Unit 因为依赖 ALU,所以暂时不能执行。
依赖解锁: 假设 ALU 的设计和调试完成了。其状态变为 COMPLETED。调度器会扫描队列,将所有依赖 ALU 的任务(比如 Fetch_Unit)的 dependencies 列表中的 1 移除。
持续执行: 这个过程不断重复,直到所有底层和中层模块都完成,最终解锁了顶层模块 RISC-V_CPU (id: 0),进行最后的集成。
Data is all you need
问题背景
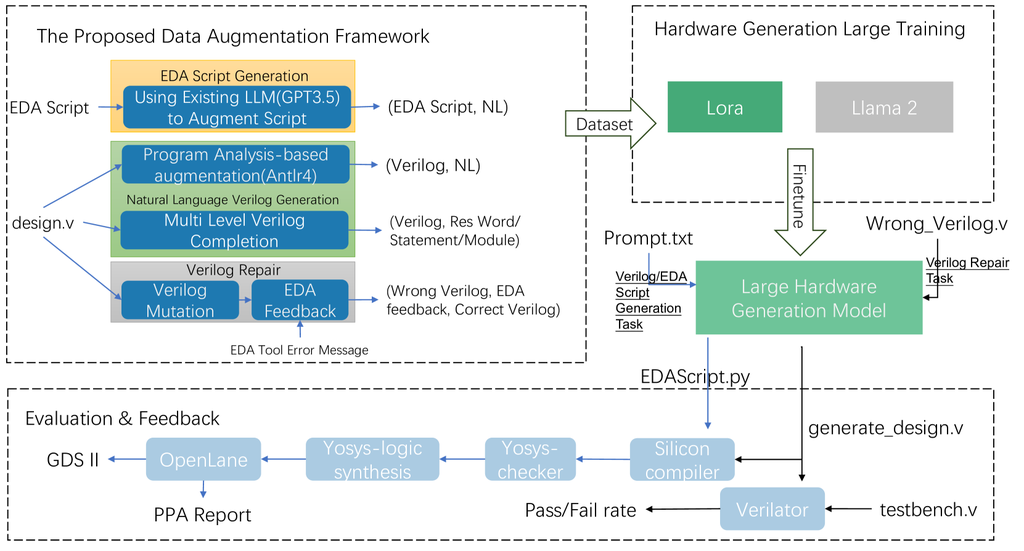
NOTE
高质量Verilog 数据的缺乏阻碍了 LLM 生成 verilog 代码质量进一步提高,本文提出了一种自动化设计数据增强框架,该框架生成与 Verilog 和 EDA 脚本对齐的大量高质量自然语言数据。
- 对于Verilog 代码生成,它将 Verilog 文件转换为抽象语法树,然后使用预定义模板将节点映射到自然语言。
- 对于 Verilog 代码修复,它使用预定义规则生成错误的 Verilog 文件,然后将 EDA 工具反馈与正确和错误的 Verilog 文件配对。
- 对于 EDA 脚本生成,它使用现有的 LLM(GPT-3.5)来获取脚本的描述
核心方法论 (Automated Design-Data Augmentation Framework)
为了解决上述问题,作者设计了一个创新的自动化数据生成框架,针对三种不同的芯片设计任务生成高质量的训练数据:
Verilog 代码生成 (Natural Language to Verilog):
方法:采用一种 基于程序分析(Program Analysis) 的方法。它使用解析器(ANTLR 4)将已有的高质量 Verilog 代码转换成抽象语法树(AST)。然后,通过预定义的规则和模板,将语法树的各个节点(如模块声明、端口定义、always 块等)自动翻译成结构化的自然语言描述。 效果:这样就从现有的 Verilog 代码中,自动创造出了大量精确对齐的“自然语言描述”和“Verilog 代码”数据对,解决了数据对齐的难题。 Verilog 代码修复 (Verilog Repair):
方法:采用一种 “先破坏,后修复” 的策略。首先,它对正确的 Verilog 代码进行程序化地“突变”(mutation),故意引入各种语法或逻辑错误(如删除关键字、修改变量位宽、移除逻辑条件等),生成“错误代码”。然后,将这些“错误代码”输入到开源的 EDA 综合工具(Yosys)中,并捕获该工具产生的错误反馈信息。 效果:最后,将“错误代码”和“EDA 工具的错误反馈”作为模型的输入,将“原始的正确代码”作为输出,构成了一条高质量的修复训练数据。这使得模型能够学习如何根据工具的反馈来调试代码。 EDA 脚本生成 (Natural Language to EDA Script):
方法:作者观察到,现有 LLM(如 GPT-3.5)虽然直接生成高质量 EDA 脚本的能力较弱,但理解现有脚本的能力很强。因此,他们采取了 “逆向工程”的思路。他们将现有的、正确的 EDA 工具脚本(基于 Python 的 SiliconCompiler 框架)喂给 GPT-3.5,让其生成对应的自然语言描述。 效果:这样就轻松地获得了约 200 个高质量的“自然语言描述”和“EDA 脚本”数据对,用于微调自己的模型。 最终,他们使用这个框架生成的大规模数据集,对 Llama 2(7 B 和 13 B)模型进行了微调,得到的模型在 Verilog 生成、修复和 EDA 脚本生成任务上,性能均显著超过了 GPT-3.5 及其他开源基线模型。
实现阶段
两阶段微调
因为大模型往往会受到最近期训练例子的影响,因此我们先用大数量的普通数据微调模型,第二阶段再用更高质量的数据训练(这点技巧在常开颜学长的多篇论文提到,及寒武纪发的那篇强化学习后训练 qwen 中也用到)
基本训练
代码补全(Code completion)是一种在序列生成任务中被广泛使用的数据增强技术。为了增强大语言模型(LLM)预测 Verilog 代码的能力,我们采用补全作为基本方法。Verilog 补全可以形式化为:给定初始的 token 序列 ({c_0, c_1, \cdots, c_{n-1}}),预测剩余的 token 序列 ({c_n, c_{n+1}, \cdots, c_m}),其中 (c_i) 表示一个字符。在我们的框架中,补全样例如下表示:
{"instruct": "complete the next [level] of Verilog file.", "input": "[Existing Verilog]", "output": "[Predict Verilog]"}Verilog 预测数据被划分为三种代码粒度层级:模块级(module-level)、语句级(sentence-level)和 token 级(token-level)。
- 模块级预测:使用模块头(module header)来生成模块体。
- 语句级预测:在已有代码以
;结束的情况下预测下一条语句。 - token 级预测:预测下一个 token。
一个包含 (i) 个 token、(j) 条语句的 Verilog 模块可以被划分为 (1 + j + i) 个补全片段。正如表 5 中的评估结果所示,单纯依赖代码补全相比 naive Llama 2,仅使 pass rate 从 22.9% 提升到 25.7%。这一提升幅度较小,说明仅靠补全还不足以有效对齐自然语言与 Verilog 领域,因此需要额外的技术来进一步提升。
自然语言与 Verilog 对齐 —— 基于程序分析规则
为了更好地对齐自然语言和 Verilog 语义,我们开发了一套基于规则的程序分析方法,用于将 Verilog 代码翻译成结构化的自然语言描述。Verilog 文件首先通过 ANTLR 4 解析成抽象语法树(AST),然后对语法树应用翻译规则。例如,规则会将模块头:
module x(input a, output reg b);
翻译为:
“名为 [x] 的 Verilog 模块包含一个输入 [a] 和一个输出 [b]。该输出是 reg 类型。”
这一阶段可以形式化为:
[ Description = Rule (Verilog) ]
需要注意的是,这些规则集并未覆盖 Verilog 的全部语法。这与程序员在用自然语言描述 Verilog 时的习惯相似:他们通常只关注核心细节,而非完整语法。该阶段生成的训练数据格式如下:
{
"instruct": "give me the Verilog module of this description.",
"input": "[natural language]",
"output": "[Verilog file]"
}对于一个包含 (k) 个可翻译语法结构的 Verilog 文件,数据集规模会线性增加到 ()。该对齐阶段能够将 LLM 的 pass rate 从 25.7% 提升到 45.7%(表 5),相当于在仅 13 B 参数量下达到了接近 GPT-3.5 的表现。基于规则的方法有效地弥合了自然语言和 Verilog 语义之间的鸿沟。
为了更详细地展示该技术,我们在一个 Verilog 模块上进行了案例分析。如图 5 所示,该模块首先通过 ANTLR 解析为抽象语法树。随后对语法结构应用规则来提取语义信息,例如:
-
模块与端口声明:将模块声明编译为自然语言。
-
例如,
module counter(clk, rst, en, count)被翻译为:“The Verilog module with name [x] has one input [a] and one output [b]. The output is reg”
-
-
always 块声明:将 always 块的声明编译为自然语言。
-
例如,在图 5 中,该 always 块被翻译为:
“The sensitive list in first trigger block is on the positive edge of clk。”
-
-
变量声明:将变量声明编译为自然语言。
-
例如,在图 5 中,数据增强框架输出:
“Output signal count has 2-bit width in range 1:0. It is a reg variable”
-
该论文并通过消融研究表明,基于程序分析的对齐阶段至关重要——仅根据完成数据训练的模型通过率仅为 25.7%,而增加对齐阶段后性能提升至 45.7%。
LPCM
一份计划书,提出了一个三个渐进的自主级别构建与六个相互关联的模块。
1 . AI 生成 HDL,编译器后端
这是 AI 最基础但也是最直接的发力点,旨在打破人与机器、高级语言与底层硬件之间的沟通壁垒。
自然语言到硬件代码: 将设计师用自然语言描述的高级需求(例如:“我需要一个 8 位宽、支持流水线的累加器”)直接翻译成精确的 Verilog 或 VHDL 硬件描述语言代码(HDL 生成模块)。 高级语言到机器指令: 自动为全新的、定制化的 CPU 指令集(ISA)生成配套的编译器。设计师只需提供新指令集的规范,AI 就能生成编译器后端,让高级语言能跑在新硬件上(编译器模块)。 复杂代码到抽象模型: 自动分析一个完整的软件应用程序(如 C/C++代码),理解其内在的计算逻辑和数据依赖关系,并将其转换成一个更易于分析的“任务图”模型(软硬件划分模块)。
2 . AI 生成模拟器配置文件和运行脚本
这个角色旨在将设计师从大量重复、繁琐且极易出错的手动劳动中解放出来,大幅提升效率。
自动化配置与脚本编写: 自动生成复杂模拟器(如 Gem 5)的配置文件和运行脚本,让设计师从繁琐的环境搭建中解脱出来(模拟器模块)。 自动化性能分析: 自动运行程序并识别出其中的性能瓶颈或最值得用硬件加速的“热点代码”,而无需工程师手动插桩和分析(二进制翻译与软硬件划分模块)。 自动化纠错与迭代: 在生成 HDL 代码后,自动调用 EDA 工具进行验证,如果发现语法错误或时序违例,AI 能够理解错误报告并自我修正代码,形成一个快速的闭环迭代过程(HDL 生成模块)。
3 . AI 自行做 trade off
这是 AI 最高级的角色,利用其强大的学习和推理能力,在海量的可能性中做出最佳的、全局性的权衡与决策。
探索巨大的设计空间: 在数百万甚至数十亿种硬件参数组合(如核心数、缓存大小、总线宽度等)中,智能地进行搜索,以找到在性能、功耗、面积(PPA)约束下的最佳平衡点(设计空间探索模块)。 做出最佳软硬件划分: 基于对任务图的分析和性能预测,AI 能够决定应用程序的哪些部分用软件实现成本最低,哪些部分用硬件加速收益最大,做出全局最优的划分决策(软硬件划分模块)。 实现跨层级协同优化: AI 在做上游决策时(如编译器优化),就能预见到这些决策对下游(如最终芯片布局)的影响,从而打破传统设计流程中各环节相互割裂的“筒仓效应”,实现真正的端到端全局优化。
4 . AI 作为人来管理整个系统
这个角色确保了上述所有能力能够被有机地整合在一起,形成一条流畅、自动化的流水线。
担当流程“总指挥”: AI 作为智能体(Agent),负责协调编译器、模拟器、DSE 等六大模块的工作,管理它们之间的数据流转和任务交接,确保整个流程顺畅运行。
管理闭环反馈系统: 整个 LPCM 框架是一个大的闭环系统。AI 负责管理这个反馈循环:模拟器的结果反馈给 DSE,EDA 工具的结果反馈给 HDL 生成器,使得系统能够不断地自我学习和进化。
结果
3DGS 案例研究通过 LPCM 框架展示了显著的性能提升。自动模拟器配置成功地使用 DeepSeek-V3 生成了定制的 GEM5 模拟脚本,无需进行微调,并通过了所有 3DGS 工作负载测试以确认其有效性。
总结
共同的思想
- 分拆需求,chipgpt 中接口拆分,autosilicon 中任务拆分,data is all you need 中也注重先用解析器处理 verilog 再用模版文件处理结构化数据。
- 将 PPA,模拟器,波形,PPA 等纳入闭环中,即将 LLM 放在带有编译/仿真/综合反馈的闭环里。
一些猜想
LLM-aware IR
论文 data is all you need 中用到“高质量 Verilog 代码转换成抽象语法树(AST)。然后,通过预定义的规则和模板,将语法树的各个节点(如模块声明、端口定义、always 块等)自动翻译成结构化的自然语言描述“。
其实可以类似 mlir 一样,直接提出一种新的语言 LLM-aware IR 为 verilog 和 LLM 间搭建一个中间层(其实很像 LPCM 这篇论文里提出的要做的 LLM 编译器中可能会需要的组件)。在有这种 LLM-aware IR 的基础上去构建新的编译器。
但不限于 verilog 的生成,而是 LPCM 的全流程中的操作比如二进制翻译,模拟器配置文件生成等等都拆分做成 LLM-aware IR 中的算子库,由大模型编译器接收到目前工作流程中的状态去路由这些算子库中的算子生成具体操作。
(但其实这个也难说,因为大模型的内部存在自己的语言,不是 json 也不是 toml 等等,比如说 claude,本来在模型更新的 prompt 模块工作状况良好,在模型更新后(当然不排除是因为推理成本降低导致的能力下降),总之同样的 prompt 模版对于不同的模型存在差异,很难保证稳定,或者说让这个 LLM-aware IR 也参与到修改回路中,就像大模型的 QK 和 FFN 一样在训练中动态调整)
仔细看了 LPCM 后发现 IR这条思路 LPCM 也提到了。
多模态数据
本来想说把网表文件纳入训练数据,用 GNN 去捕捉电路结构信号(LPCM 也提到了),这篇文章太厉害了,基本上是该领域的综述了。
暗信息
或许还应该把开源芯片社区中的开发文档,以及 GitHub 仓库中的提交与 commit 都作为训练材料,甚至大量体系结构相关的书籍。这也是第三级别的应有之义(这些总算是 LPCM 没提到的了),及由大模型去生成总结出芯片设计中的经验模版。