Make LLM Inference Affordable to Everyone: Augmenting GPU Memory with NDP-DIMM
-
确定最佳神经元划分。首先,将活跃神经元和非活跃神经元在GPU和NDP-DIMM之间划分的标准对于计算效率至关重要。例如,如果仅将活性最低的神经元预测为“活跃”神经元,这将给有限的GPU内存带来压力。相反,将频繁激活的神经元分配到“非活跃”区域将使计算能力有限的NDP-DIMM承受过多的计算负担。因此,确定最佳神经元划分策略至关重要。然而,由于输入的特定性,活跃/非活跃神经元的划分无法完全预先确定。这需要一种精确但轻量级的在线预测,以实现对活跃/非活跃神经元划分进行实时调整,并将迁移成本降至最低。
-
利用多个NDP-DIMM有限的计算能力。 与单个GPU提供的数百TFLOPS相比,NDP-DIMM上的计算能力限制在数百GFLOP。 因此,即使用于处理不频繁激活的神经元,NDP-DIMM仍然成为推理性能的瓶颈。 因此,充分发挥NDP单元的计算效率至关重要。 具体来说,由于我们需要使用多个DIMM共同支持大型LLM,因此每个NDP-DIMM上的计算负载应保持平衡。 然而,由于激活神经元的动态性,在推理过程中,一些NDP-DIMM超负荷运行,而另一些则未充分利用。 因此,主要挑战在于实现NDP-DIMM之间计算负载平衡的在线调度。
大语言模型中内在的稀疏性
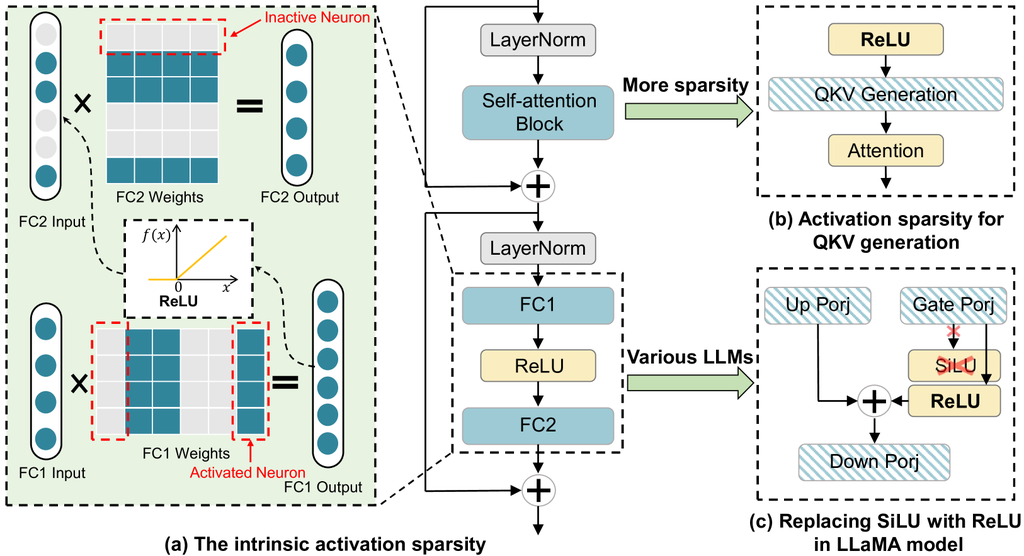 本来 Transformer 架构中就有 Relu (两个全连接层中)具有稀疏性可以把哪些变成 0 的向量作为冷节点不参与计算不搬运(进一步在 QKV 生成前也插入 ReLU 甚至把现有的 llama 架构中的 swilu 也换成 ReLU)
本来 Transformer 架构中就有 Relu (两个全连接层中)具有稀疏性可以把哪些变成 0 的向量作为冷节点不参与计算不搬运(进一步在 QKV 生成前也插入 ReLU 甚至把现有的 llama 架构中的 swilu 也换成 ReLU)
基于 off-loading 的大模型推理系统
为了让消费级的 GPU 跑得动超大模型(例如 LLaMA2-70B)参数量巨大,需要数百 GB 显存),提出了 off-loading 技术把模型部分参数存放在主机内存,在推理阶段动态加载所需部分到GPU上执行。但受限于 PCIe 速率
本文于是举了现有的几种 off-loading 路线,以及大模型推理阶段的访存特性与各种方案的优劣。
这篇博客介绍了大模型推理的一切 https://jax-ml.github.io/scaling-book/inference
通过比较大模型的训练与推理阶段,可以发现两者在系统特性上存在显著差异。训练阶段通常采用大批量输入,包含前向传播和反向传播,因而每一层权重在一次迭代中会被多次使用(forward/backward),数据搬运的开销可以被大量计算所摊薄,系统的主要瓶颈在于 GPU 算力和显存容量。相比之下,推理阶段只涉及前向传播,且生成过程具有严格的自回归依赖性(token-by-token),导致每层权重在处理单个 token 时几乎只使用一次。再加上推理场景往往是交互式的小 batch,这使得计算负载不足以掩盖频繁的参数搬运开销,最终系统性能直接受制于 CPU–GPU 之间的 PCIe 带宽。
因此,许多源自训练系统的 offloading 技术在推理中效果有限。以 Hugging Face Accelerate 为例,其参数分区与动态加载策略在训练中能够较好地利用 GPU 内存与 host 内存,但在推理场景下,由于权重复用度极低和计算规模有限,PCIe 传输成为瓶颈,性能下降明显。这也解释了为什么 FlexGen 需要通过 block-based 处理和重叠调度来提升推理阶段的吞吐量。整体来看,训练优化侧重吞吐,推理优化侧重延迟,二者在系统设计上的差异决定了不能直接照搬相同的 offloading 方法。
针对推理阶段频繁参数加载与 PCIe 带宽受限的问题,FlexGen 和 Deja Vu 提出了不同的优化思路。FlexGen 通过 block-based 与 overlap 调度,将多个 token 组合为一个处理块,在同一层权重加载后一次性完成多个 token 的计算,并在计算过程中并行预取下一层参数,从而显著减少了频繁的数据搬运并部分掩盖传输延迟。这一策略在大 batch 或 prefill 阶段尤为高效,因为充足的计算量能够有效 amortize 数据传输开销。然而,在交互式本地推理场景中,由于 batch size 极小,FlexGen 的优势难以体现。
Deja Vu 则从计算稀疏性出发,利用神经元激活的动态稀疏特性,仅预测并加载真正会被激活的部分权重,从而减少无效计算和无用的数据传输。这一方法在理论上能够降低推理成本,但由于激活模式难以提前预加载,仍需要频繁地从主机内存读取动态子集参数,其性能依旧受制于 PCIe 带宽。
整体来看,现有 offloading 技术确实能够解决 GPU 显存不足的问题,使消费级硬件具备运行超大模型的能力,但推理阶段由于缺乏权重复用和大规模并行,PCIe 带宽瓶颈始终未能根本解决。这表明未来的研究需要在模型结构优化(如稀疏化、模块化) 与系统层面的硬件接口改进(如更高带宽互联、near-memory computing) 之间寻求新的平衡,以真正提升大模型推理的可用性与效率。
再引入存内计算,NDP-DIMM
在 sparsity 和 off-loading 都不能完全解决 PCIe,本文选择使用多个 NDP-DIMM 作为扩展内存,因为它们提供了与单一消费级 GPU 相当的带宽和更大的存储容量。