Unlocking the Hidden Potential of CLIP in Generalizable Deepfake Detection
https://www.alphaxiv.org/overview/2503.19683v2
作者的方法核心在于利用预训练的 CLIP-ViT-L/14 图像编码器作为特征提取器,并结合策略性微调和正则化技术以增强泛化能力。
作者没有采用完整模型微调(这有在有限的深度伪造数据上过拟合的风险),而是将 LN-tuning 作为其主要的参数高效微调(PEFT)策略。这种方法仅微调视觉编码器中的层归一化参数,在总计 3.03 亿参数中引入了大约 10.4 万个可训练参数(0.03%)。这种选择性训练保留了 CLIP 可泛化的预训练表示,同时允许任务特定的适应
它并没有发明全新的算法,而是首次将三种在其他领域(如人脸识别)被证明有效的技术,巧妙地组合并成功应用到了基于 CLIP 模型的深度伪造检测任务上,效果显著:
特征归一化 (Normalization):将模型提取的特征投影到一个超球面上。这是最关键的一步,极大地提升了模型的泛化能力,防止了过拟合。
度量学习 (Metric Learning):在超球面上进一步优化特征的分布,让“真”和“假”的特征分得更开,聚得更拢。
潜在空间增强 (Latent Augmentation):在特征层面直接“合成”新的伪造样本进行训练,让模型能更好地识别闻所未闻的新型伪造技术。
总而言之,它的创新之处在于证明了用这套简单而经典的“组合拳”,就能让一个通用大模型(CLIP)在深度伪造检测任务上达到甚至超越许多复杂的专用模型,为领域内树立了一个强大又简洁的标杆。
该模型在 FaceForensics++(c 23 压缩)上进行训练,并使用自定义验证集,该验证集结合了 FF++测试样本和附加数据集,以更好地反映分布外性能。训练使用 Adam 优化器,采用余弦学习率调度和标准图像增强。 评估遵循跨数据集协议以评估泛化能力,在 Celeb-DF-v 2、DFDC、Google 的 DFD、FFIW 和 DeepSpeak v 1.0 上进行测试。主要指标是视频级别的 AUROC,通过平均每个视频所有采样帧的预测值计算得出。
可以看该论文由 ai 生成的 blog 与开源的代码 https://github.com/yermandy/deepfake-detection?tab=readme-ov-file
不过话又说回来这篇论文不如另一篇
Effort: Efficient Orthogonal Modeling for Generalizable AI-Generated Image Detection 获得了 icml 2025 的 spotlight https://www.alphaxiv.org/abs/2411.15633v1
感觉有点像把大模型领域已经用过的很多方法再在 deepfake detection 用一遍跑一下[捂脸]
复现的环境配置
重庆地区的一台 NVIDIA GeForce RTX 4090(后面因为要微调训练跑 PEFT 更换成上海地区的H20)
需要解决一些命令行工具的镜像问题(一般在我自己的机器上我会选择终端挂代理,毕竟有些镜像同步的有问题)
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.50, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
merges.txt: 525kB [00:00, 2.89MB/s]
Traceback (most recent call last):
File "/root/along/deepfake-detection/inference_torchscript.py", line 22, in <module>
preprocess = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/miniconda3/envs/dfdet/lib/python3.12/site-packages/transformers/processing_utils.py", line 1070, in from_pretrained
args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
比如 uv huggingface 都需要配置镜像
export UV_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple
export HF_ENDPOINT=https://hf-mirror.comexport TRANSFORMERS_OFFLINE=0
TRANSFORMERS_OFFLINE 这个环境变量的作用:
| 值 | 含义 | 行为 | 适用场景 |
|---|---|---|---|
| 未设置 或 0 | 在线模式 | - 先检查本地缓存 - 如果没有对应模型或 tokenizer,会尝试从 Hugging Face Hub 下载 | 默认情况,联网训练/推理 |
| 1 | 离线模式 | - 只从本地缓存加载 - 不会尝试联网下载,若本地缺少文件会报错 | 服务器无网环境、本地缓存部署、需要严格控制依赖时 |
所以当因为网络导致的 huggingface 下载下的模型文件缺失后建议在设置好镜像后再设置一下 TRANSFORMERS_OFFLINE=0 |
某个镜像站因为访问太多被限制后可以换着用
HF_ENDPOINT=https://huggingface.tuna.tsinghua.edu.cn python inference_torchscript.py最小推理验证
(dfdet) root@gpu-4090-24g-instance-4783-jvmdmc1c-7c7c75bb4f-gr65j:~/along/deepfake-detection# HF_ENDPOINT=https://hf-mirror.com python inference_torchscript.py
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.50, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
tokenizer_config.json: 905B [00:00, 4.51MB/s]
vocab.json: 961kB [00:00, 3.38MB/s]
p(real) = 0.8087, p(fake) = 0.1913, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/000.png
p(real) = 0.3680, p(fake) = 0.6320, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/045.png
p(real) = 0.1854, p(fake) = 0.8146, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/030.png
p(real) = 0.1476, p(fake) = 0.8524, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/015.png
p(real) = 0.9300, p(fake) = 0.0700, image: datasets/CDFv2/YouTube-real/00000/000.png
p(real) = 0.8800, p(fake) = 0.1200, image: datasets/CDFv2/YouTube-real/00000/014.png
p(real) = 0.6876, p(fake) = 0.3124, image: datasets/CDFv2/YouTube-real/00000/028.png
p(real) = 0.2524, p(fake) = 0.7476, image: datasets/CDFv2/YouTube-real/00000/043.png
p(real) = 0.1790, p(fake) = 0.8210, image: datasets/CDFv2/Celeb-real/id0_0000/045.png
p(real) = 0.0947, p(fake) = 0.9053, image: datasets/CDFv2/Celeb-real/id0_0000/030.png
p(real) = 0.1089, p(fake) = 0.8911, image: datasets/CDFv2/Celeb-real/id0_0000/015.png
p(real) = 0.6545, p(fake) = 0.3455, image: datasets/CDFv2/Celeb-real/id0_0000/000.png最好还是挂 clash 全局代理 (爆金币买了好的节点)
镜像站有些仓库没有同步
(dfdet) root@gpu-h20-96g-instance-4783-hnpwvuy2-6444d8fb46-hjjgx:~/deepfake-detection# python inference.py
FF-ALL-ClipL-LinearNorm-LN-CE+LS+UnAl-slerp
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
model.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████| 1.71G/1.71G [00:21<00:00, 79.1MB/s]
Using bfloat16 Automatic Mixed Precision (AMP)
p(real) = 0.8056, p(fake) = 0.1944, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/000.png
p(real) = 0.3693, p(fake) = 0.6307, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/045.png
p(real) = 0.1807, p(fake) = 0.8193, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/030.png
p(real) = 0.1456, p(fake) = 0.8544, image: datasets/CDFv2/Celeb-synthesis/id0_id1_0000/015.png
p(real) = 0.9294, p(fake) = 0.0706, image: datasets/CDFv2/YouTube-real/00000/000.png
p(real) = 0.8775, p(fake) = 0.1225, image: datasets/CDFv2/YouTube-real/00000/014.png
p(real) = 0.6610, p(fake) = 0.3390, image: datasets/CDFv2/YouTube-real/00000/028.png
p(real) = 0.2524, p(fake) = 0.7476, image: datasets/CDFv2/YouTube-real/00000/043.png
p(real) = 0.1807, p(fake) = 0.8193, image: datasets/CDFv2/Celeb-real/id0_0000/045.png
p(real) = 0.0933, p(fake) = 0.9067, image: datasets/CDFv2/Celeb-real/id0_0000/030.png
p(real) = 0.1074, p(fake) = 0.8926, image: datasets/CDFv2/Celeb-real/id0_0000/015.png
p(real) = 0.6575, p(fake) = 0.3425, image: datasets/CDFv2/Celeb-real/id0_0000/000.png开始训练
准备数据
自然,两重原因,挂完代理后少了一重,但是数据集的官网也是不堪重负,因此找到了 kaggle 仓库中的 FaceForensics++ 并且通过查阅原 paper 找到其使用的数据集压缩版本 c23
https://www.kaggle.com/datasets/xdxd003/ff-c23
记得要配置好 ~/.kaggle/kaggle.json 之后就可以通过 curl 来下载了。
(dfdet) root@gpu-h20-96g-instance-4783-hnpwvuy2-6444d8fb46-hjjgx:~/deepfake-detection# curl -L -o ~/deepfake-detection/ff-c23.zip https:/
/www.kaggle.com/api/v1/datasets/download/xdxd003/ff-c23
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
74 16.6G 74 12.4G 0 0 26.5M 0 0:10:41 0:07:58 0:02:43 26.2M处理数据
要求使用该仓库
https://github.com/SCLBD/DeepfakeBench
该仓库中已经提供好了经过处理的数据(将人脸从视频中提取出 frame 并裁剪)但是和本论文要求的目录结构不一样,所以手动调整目录结构后开始训练(也是连蒙带猜目录结构应该是怎样)
开始训练
┏━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃
┡━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩
│ 0 │ feature_extractor │ PeftModel │ 303 M │ train │
│ 1 │ model │ LinearProbe │ 2.0 K │ train │
│ 2 │ criterion │ Loss │ 0 │ train │
│ 3 │ train_step_outputs │ OutputsForMetrics │ 0 │ train │
│ 4 │ val_step_outputs │ OutputsForMetrics │ 0 │ train │
│ 5 │ test_step_outputs │ OutputsForMetrics │ 0 │ train │
└───┴────────────────────┴───────────────────┴────────┴───────┘
Trainable params: 104 K
Non-trainable params: 303 M
Total params: 303 M
Total estimated model params size (MB): 1.2 K
Modules in train mode: 118
Modules in eval mode: 346
/opt/miniconda3/envs/dfdet/lib/python3.12/site-packages/lightning/pytorch/utilities/data.py:79: Trying to infer the `batch_size` from an
ambiguous collection. The batch size we found is 12. To avoid any miscalculations, use `self.log(..., batch_size=batch_size)`.
Logs: runs/train/example-run/
/opt/miniconda3/envs/dfdet/lib/python3.12/site-packages/lightning/pytorch/utilities/data.py:79: Trying to infer the `batch_size` from an
ambiguous collection. The batch size we found is 128. To avoid any miscalculations, use `self.log(..., batch_size=batch_size)`.
Epoch 0/9 ━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 129/1331 0:01:05 • 0:10:10 1.97it/s train/loss_step: 0.608 train/loss_ce_step: 0.608
train/alignment_step: 0.602 train/uniformity_step:
-1.188
训练过程
可以在该链接下查看训练时各指标变化图 https://wandb.ai/alongforllm-ucas/deepfake?nw=nwuseralongforllm
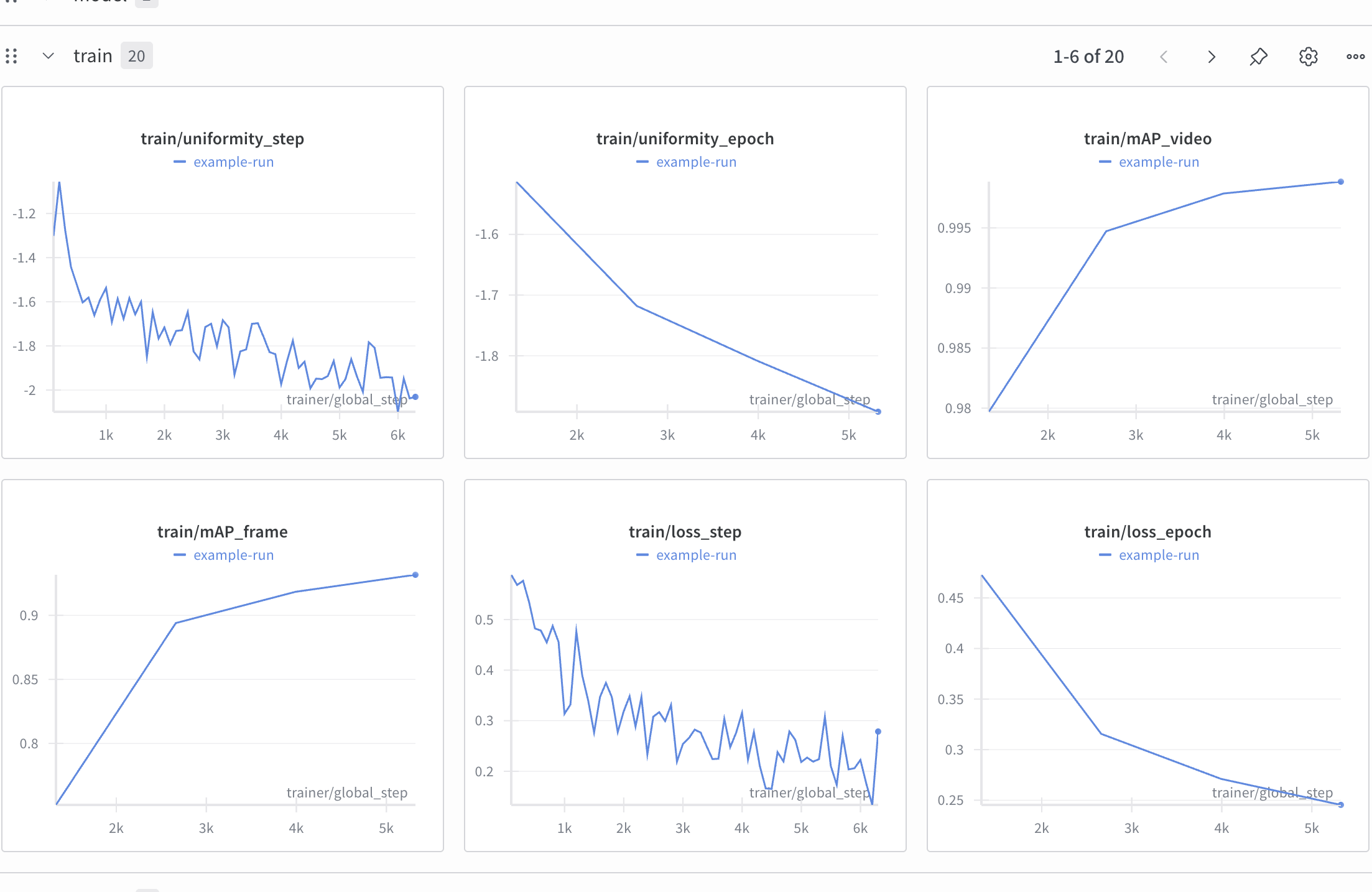
最终测试
训练到第 7 个 epoch 程序卡死了(nvidia 显存占用也为 0),强制退出后就用当前的 checkpoint 来进行测试
python run.py --test
测试集和训练集独立,当然该仓库的问题是测试集中的样本数量比较少。(得到的 1.0 分数很可能是在这个特定的小样本上的一种“偶然的完美表现”。)
Logs: runs/test/example-run/
/opt/miniconda3/envs/dfdet/lib/python3.12/site-packages/lightning/pytorch/utilities/data.py:79: Trying to infer the `batch_size` from an
ambiguous collection. The batch size we found is 12. To avoid any miscalculations, use `self.log(..., batch_size=batch_size)`.
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ num_test_files │ 12.0 │
│ test/acc_frame │ 0.75 │
│ test/acc_video │ 0.6666666865348816 │
│ test/alignment │ 0.6961564421653748 │
│ test/auroc_frame │ 0.8125 │
│ test/auroc_video │ 1.0 │
│ test/balanced_acc_frame │ 0.75 │
│ test/balanced_acc_video │ 0.75 │
│ test/dataset/CDF/acc_frame │ 0.75 │
│ test/dataset/CDF/acc_video │ 0.6666666865348816 │
│ test/dataset/CDF/auroc_frame │ 0.8125 │
│ test/dataset/CDF/auroc_video │ 1.0 │
│ test/dataset/CDF/balanced_acc_frame │ 0.75 │
│ test/dataset/CDF/balanced_acc_video │ 0.75 │
│ test/dataset/CDF/eer_frame │ 0.25 │
│ test/dataset/CDF/eer_video │ 0.0 │
│ test/dataset/CDF/f1_score_frame │ 0.7333333492279053 │
│ test/dataset/CDF/f1_score_video │ 0.6666666865348816 │
│ test/dataset/CDF/mAP_frame │ 0.8417658805847168 │
│ test/dataset/CDF/mAP_video │ 1.0 │
│ test/eer_frame │ 0.25 │
│ test/eer_video │ 0.0 │
│ test/f1_score_frame │ 0.7333333492279053 │
│ test/f1_score_video │ 0.6666666865348816 │
│ test/loss │ 0.5597330927848816 │
│ test/loss_ce │ 0.5597330927848816 │
│ test/mAP_frame │ 0.8417658805847168 │
│ test/mAP_video │ 1.0 │
│ test/uniformity │ -1.2965565919876099 │
└─────────────────────────────────────┴─────────────────────────────────────┘