OpenAI Triton 是目前比较流行的用来高效写CUDA Kernel的一个工具,当然随着它的大幅被采用(尤其是被Pytorch采用),也有很多硬件公司开始基于它来做二次开发,比如增加自己的硬件后端。总的来说,Triton是一个很不错的工具,也值得我们去了解的一个东西。
目前网上其实已经有不少的介绍Triton源码以及思想的优秀文章,我在这里就不再赘述了,那本篇文章将会采用一种方式,秉承Learning by Doing的思想来理解Triton做了什么,即我们将会实现一个非常非常非常迷你的类Triton的编译器来理解Triton链路,希望能对大家后续深入理解Triton以及类似的编译器带来一些帮助。
Triton本质上其实还是没有逃脱编译器的核心思想,我觉得这是首先需要最树立的核心点,只是用于了深度学习模型这个场景,相比传统编译器来了一点更新鲜的Buff加成。编译器针对一种编程语言的过程,从大的来说,我们可以分为三大阶段:编译器前端 → 编译器中端 → 编译器后端,输入是程序源代码,输出是机器码。
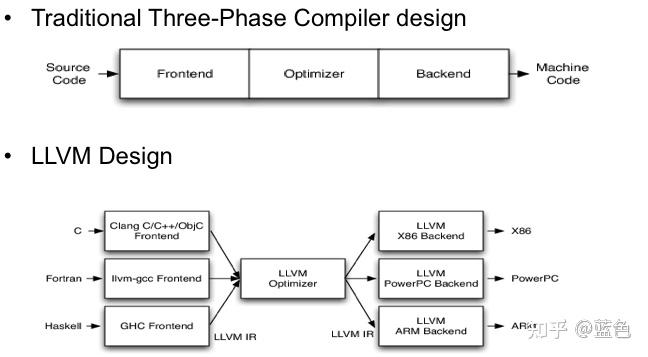
编译器三个阶段与LLVM
如果再往细了说,编译器前端一般分为,词法分析 → 语法分析 → 语义分析 → 中间代码(IR, Intermediate Representation)生成;编译器中端一般会做IR的优化变换,并且是机器无关的优化,如公共子表达式消除, 死代码消除等,编译器后端一般包含机器相关的优化以及代码生成(如寄存器分配、指令调度、汇编/机器代码生成等),这里面其实最核心的是IR,它起着承上起下的作用,并且在很多编译器中会有多种IR。有关这些细节我不再深入,因为不是我们这篇文章的重点,但是如果感兴趣的读者可以翻阅[编译原理](编译原理)书籍或者我之前写的一些文章作为补充了解,如 编译器概述, 词法分析原理, LLVM CodeGen 等进行一些补充阅读。
Triton本质上则是完成了这一过程的一个编译器体现,只是结合深度学习场景以及融入已有的深度学习生态习惯,它借用了一些成型的工具以及跳过了某些阶段。那么,接下来,我们就话不多说,直接开干。
深度学习目前的生态语言是Python,所以我们针对深度学习的场景,若要扩展写算子的能力,无疑需要架设在Python的生态上。所以,以Triton为代表的编译器,使用的方式为添加 decorator ,然后Hook走自己的路线,即 @trion.jit 。所以我们实现的第一步即,我们需要有一个 jit 作为Python函数的 decorator 可以接管函数的下一步流程。
首先让创建一个 01.py ,里面有我们的目标函数 add,然后很简单,函数实现就为一个 print("add")
01.py
def add():
print("add")
我们接下来需要创建一个 jit 函数来接管它。
def jit(fn):
def inner():
print("jit is called")
return inner
@jit
def add():
print("add")
add()
让我们运行 python 01.py ,可以看到 jit is called ,而没有输出 add ,说明我们将add已经得执行接管到了 jit. 那么这里的逻辑很简单, @jit 的 fn 参数会接收 add 这个function object,然后我们的处理逻辑则是返回了一个内部函数 inner ,当我们调用 add() 的时候,其实等价于调用了 inner ,于是我们打印了 jit is called 。为了避免这篇文章特别冗长以及变为Python语法的普及文章,于是我这里点到为止,有关 decorator 的知识可以参阅这一篇 Python Decorators 进行补充,后续涉及到 decorator 的执行逻辑将不会做过多阐释。
万里长征,我们已经完成了第一步,就这么简单,不复杂。接下来,我们开始我们的第二步,我们需要把我们的 fn 函数用起来。那么我们这一步要做的就是解析 fn ,完成词法分析与语法分析。对于初学者来说,不要太过惊讶,似乎感觉刚教会1+1=2,你就让我去做微积分。其实不然,我们不需要真正的实现词法分析器与语法分析器,正如上文所说,我们架设在Python这个生态,我们可以利用一些工具来帮助我们完成这个工作,但是我们要知道词法分析器与语法分析器是做什么的,以及产生的是什么,会更好的理解,这里都在上面的文章有提到,这里我就简单的提一下,词法分析器主要完成字符的识别,组成合理的词素,最后输出一系列的词法单元(Token),如这里我们会识别 d,e,f ,然后组成 def 关键词这一个词素。语法分析器则会拿着这些词法单元的组合,来看是否符合程序语言的规则,最后产生抽象语法树(Abstract Syntax Tree, 简称AST)。那么我们这里要做的就是利用Python已有的工具产生AST。
02.py
import inspect
import ast
def jit(fn):
def inner():
fn_src = inspect.getsource(fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
return inner
@jit
def add():
print("add")
add()
这里的改动主要在 inner 函数,我们拿到 fn 以后,通过 inspect 的 getsource 函数转为 string 格式,然后将其给与 ast 的 parse 函数,从而获得抽象语法树AST。最后,我们使用 print 和 ast.dump 将结果打印出来,可以看到以下的结果:
Module(body=[FunctionDef(name=‘add’, args=arguments(posonlyargs=[], args=[], vararg=None, kwonlyargs=[], kw_defaults=[], kwarg=None, defaults=[]), body=[Expr(value=Call(func=Name(id=‘print’, ctx=Load()), args=[Constant(value=‘add’, kind=None)], keywords=[]))], decorator_list=[Name(id=‘jit’, ctx=Load())], returns=None, type_comment=None)], type_ignores=[])
有关Python AST的更多信息,可以参考[Python文档](docs.python.org/3/libra)的介绍,我这里则不再赘述。
通过上面的代码,我们回想前面谈到的编译原理,可以发现,我们通过使用已有的Python库,完成了词法分析以及语法分析的过程,那么我们其实编译器前端还剩下什么呢?就是语义分析和代码生成。何谓语义分析?其实就是在符合我们程序语言的语法规则下,进行审查是否有语义错误(如数组下标的类型使用了浮点类型,而非整型),也会为下一阶段的代码生成做更多的准备。代码生成其实可玩的就有很多了,因为选择面很大,其实既有传统编译器所述的,选择了一种中间表示(IR),如LLVM IR,也可以选择一种程序语言(如C)做源源翻译,无论如何,这里的选择跟你的目的息息相关。那么Triton则将IR选择了MLIR,而Triton定义的 ttir / ttgir 等为MLIR Dialect。那么,为了简化,我们这里将不会抽象出单独的语义分析器(Semantic Analyzer),如Triton的[Semantic](github.com/triton-lang/),我们将会直接做代码生成这一步骤。
但是开始之前,我们将一些我们之前的 02.py 做一下小重构,抽象出一个 JIT 类来做接下来的工作,这便于我们后续的工作
02.py
def jit(fn):
return JIT(fn)
class JIT:
def __init__(self, fn):
self.fn = fn
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
@jit
def add():
print("add")
add()
这里和之前我们纯粹的 inner 是等价的,但是将会更加的干净,将代码生成的逻辑可以比较纯粹的归类于`JIT`类中。
代码生成总会有一个硬件平台目标,如Triton则是主要用于Nvidia GPU平台,那么我们这个代码生成也将会支持Nvidia GPU平台,但是我们也会支持CPU平台,那么我们可以为我们的`@jit`增加一个`target`参数,来告诉我们这个函数的目标平台是什么,这里我们将这个`target`的默认目标平台定为我们的本地CPU.
03.py
import inspect
import ast
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
@jit(target="cpu")
def add():
print("add")
add()
这里实质更好的做法是需要抽象出我们自己的 target device type ,做必要的 target 检查,但是我们这里就一切从简,就是简单的字符串,然后做个字符串的判断,表示我们的意图即可。而这段代码逻辑比较简单,就是将我们的 target 和 add 可以通过 decorator 传递到我们的 JIT 类中。
接下来我们将完成我们的大头,即我们的代码生成的工作。如前文所述,代码生成的IR选择非常的关键,需要仔细的思考,以Triton为例,则是选择了MLIR作为它的IR表示,那么我们是不是也选择MLIR呢?既然说出这句话,相信大家也知道,我不想选择MLIR,没错,我们要选择的IR是TVM的IR。对于Triton,的确是有一些设计上的考虑我并不完全赞同,当然这是我的一些个人看法,并不是说Triton不好。首先,我们要考虑我们这个东西的主要用户是什么,Triton的MLIR路线,其实坦白说,更偏向于底层编译器人员(非常类似TVM的TE或者手写TensorIR的方式),而我更认为这个东西应该要做的更偏向上层算法业务开发人员。所以针对GPU,我认为可以吐出CUDA代码是一个对算法业务开发人员更友好的方式,而非IR,我认为IR是编译器开发人员喜欢的,而不是大部分算法开发人员喜欢的。其次,我并不喜欢暴露太多细节的做法,如显示的Load / Store / GPU block size等,这也很偏底层编译器开发人员,从算法业务开发角度来说,大部分的人更喜欢纯粹的Pythonic。于是,在我们实现的时候,我们尽量让我们的这个东西可以更好的表达这个理念。当然,你说我们选MLIR能不能封装的很好,或者说往Triton上面再包一层是不是可以做到做到我们说的这些,理论上也是可以的,但是这里我们选择TVM的IR可以做的更容易一些。那么TVM的IR其实有底层的TIR,其实也有高层的Relax,那么我们这里选择的是Relax,有关TVM Relax、TensorIR等知识我这里不再赘述,感兴趣的同学可以参阅 [Relax](金雨辰:Relax: TVM 的下一代图层级 IR)、[mlc-ai](mlc.ai/zh/index.html)等。
代码生成的输入是AST,目标是IR,所以我们接下来要做的工作其实很Naive,即遍历我们的AST,然后不断的吐出我们的IR指令即可,与此同时,每一个IR都会有自己的IR范式,这些功能都可以通过IR的IRBuilder来做到,于是我们的工作就变为了遍历AST,然后使用IRBuilder构建等价的(优化的)IR出来。Python则为这个提供了很方便的一个基类 ast.NodeVisitor ,我们只需要继承这个基类,然后 override visit_XXX 即可以完成我们的目的。
04.py
import inspect
import ast
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
code_generator = CodeGenerator(fn_ast, self.target)
code_generator.code_gen()
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, target):
self.fn_ast = fn_ast
self.target = target
def code_gen(self):
self.visit(self.fn_ast)
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
@jit(target="cpu")
def add():
print("add")
add()
这里的逻辑很简单,基本体现了我们上文的描述,即我们有一个新的 CodeGenerator 类,然后接收了AST以及相应的Target,然后我们基于 ast.NodeVisitor ,通过 visit 方法去遍历这个AST,这里当然还没有真正有意义的逻辑,仅仅是 print ,然后我们通过`code_gen`方法暴露给外部。那么我们运行这个程序,可以得到类似的输出:
Module(body=[FunctionDef(name=‘add’, args=arguments(posonlyargs=[], args=[], vararg=None, kwonlyargs=[], kw_defaults=[], kwarg=None, defaults=[]), body=[Expr(value=Call(func=Name(id=‘print’, ctx=Load()), args=[Constant(value=‘add’, kind=None)], keywords=[]))], decorator_list=[Call(func=Name(id=‘jit’, ctx=Load()), args=[], keywords=[keyword(arg=‘target’, value=Constant(value=‘cpu’, kind=None))])], returns=None, type_comment=None)], type_ignores=[])
Visit Module
Visit FunctionDef
Visit arguments
Visit Expr
Visit Call
Visit Name
Visit Load
Visit Constant
Visit Call
Visit Name
Visit Load
Visit keyword
Visit Constant
接下来我们则是要使用我们的 Relax IRBuilder 来通过构建 Relax ,所以我们需要了解 Relax 的基本构造以及与这里AST的对应关系,这里依然希望大家可以先阅读之前提到的 [Relax](金雨辰:Relax: TVM 的下一代图层级 IR)、[mlc-ai](mlc.ai/zh/index.html),我相信足够理解了。
接下来我们准备一下TVM,我这里使用的commit是4a5e22e869e92b9c12b3bda8b88a0ce8c69b8d30,理论上使用最新的也没有什么大问题,有关如何编译TVM,也请参阅[TVM的官方文档](Install from Source),这里我就不再赘述,只是注意需要将 USE_LLVM 和 USE_CUDA 配置记得打卡,因为我们需要支持CPU和GPU。
那么我们接下来进行我们代码生成的下一步,将我们的AST真正的翻译到我们的 Relax 中。
05.py
import inspect
import ast
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
code_generator = CodeGenerator(fn_ast, self.target)
code_generator.code_gen()
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, target):
self.fn_ast = fn_ast
self.target = target
self.ib = IB()
self.ir_module = None
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
pass
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
@jit(target="cpu")
def add():
print("add")
add()
在这里,我们开始完成具体的一些工作,如添加我们的 IRBuilder,将Python的 Module 翻译为 IRModule 等。这里面对于习惯了LLVM的[IRBuilder](llvm::IRBuilder< FolderTy, InserterTy > Class Template Reference)的同学的确会需要转一下方式,在LLVM中,一般会习惯 ib.CreateXXX 来创建指令,但是在TVM这里不是这样,而是以 Frame 的方式来构建, Frame 里面包含新的 Frame 或者具体的 IR instruction ,然后将各种 Frame 放置在 IRBuilderFrame 里面,构成一个 Stack Frame ,如
from tvm.script.ir_builder import tir as T
from tvm.script.ir_builder import IRBuilder
with IRBuilder() as builder:
with T.prim_func(...): # pushes a PrimFuncFrame (subclass of IRBuilderFrame)
# to \`builder\`'s stack of frames
buffer = T.match_buffer(...)
return builder.get() # returns the constructed IR, i.e. tir.PrimFunc
所以在我们这里,我们将我们要生成的 IR 放在 with self.ib Scope 中,最后使用 self.ib.get() 返回我们构建好的 IRModule ,随后我们可以使用 print 来查看生成好的结果。那么我们这里其实只真正翻译了 Module ,遇到 FunctionDef 时,我们就仅仅是 Pass ,然后就中断了遍历过程。那么我们运行可以看到如下的结果:
...
Visit Module
Visit FunctionDef
# from tvm.script import ir as I
@I.ir_module
class Module:
pass
可以看到我们的确完成了初步的 IRModule 的构建。那么我们接下来开始做更多的事情,翻译 FunctionDef
06.py
import inspect
import ast
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
code_generator = CodeGenerator(fn_ast, self.target)
code_generator.code_gen()
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, target):
self.fn_ast = fn_ast
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_Pass(self, node: ast.Pass):
pass
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
@jit(target="cpu")
def add():
pass
add()
在该例子中,为了更方便的简化我们的问题,我们将 add 函数的 print 改为了 Pass ,然后我们要实现的 FunctionDef 的内容就比较简单了,即只需要翻译 Pass 语句就好了。从我们的代码可以看出,我们针对 visit_FunctionDef 开始引入了 Relax Function 的相关构造,这里,我们同样构造了一个 Relax FunctionFrame 对应于我们的`add`,随后设置了函数名称等信息,然后开始进行函数体的生成。这里可以看到,我们预留了 self.entry 作为我们后续的入口,即我们 add 函数,以及我们这里针对我们函数的return,预留了一个 self.ret 。这里有一个小的Hack,因为Relax函数必须要一个Return,所以针对没有返回值的情况,我们返回了一个无意义的 ShapeExpr([]). 然后我们运行可以看到如下的结果:
Visit Module
Visit FunctionDef
Visit Pass
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def add() -> R.Shape([]):
return R.shape([])
我们看到我们在 IRModule 里面已经有了 Relax Function 的相关生成。
接下来,我们要做点更有意义的事情,即我们要生成一个 1 + 1 ,存储在一个变量中,随后将这个变量结果返回出去。这里就需要涉及到 Assign / add 以及编译原理中的 Symbol Table ,当然这里我们为了简化,暂时可以把这个 Symbol Table 做的非常的简单。
07.py
import inspect
import ast
from typing import Dict, Any
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
code_generator = CodeGenerator(fn_ast, self.target)
code_generator.code_gen()
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, target):
self.fn_ast = fn_ast
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
self.local_var_table : Dict[str, Any] = {}
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_Pass(self, node: ast.Pass):
pass
def visit_Assign(self, node: ast.Assign):
if len(node.targets) != 1:
raise NotImplementedError("Doesn't support simultaneous multiple assignment like 'a = b = c' in AST node type: {}".format(type(node).__name__))
target: rx.Var = self.visit(node.targets[0])
value = self.visit(node.value)
self.local_var_table[target.name_hint] = value
self.ib.name(target.name_hint, value)
def visit_Name(self, node: ast.Name):
name = node.id
if isinstance(node.ctx, ast.Store):
if name not in self.local_var_table.keys():
self.local_var_table[name] = rx.Var(name, struct_info=rx.ObjectStructInfo())
return self.local_var_table[name]
def visit_BinOp(self, node: ast.BinOp):
lhs = self.visit(node.left)
rhs = self.visit(node.right)
return R.emit(self._binOp_maker(node.op)(lhs, rhs))
def visit_Return(self, node: ast.Return):
ret_value = self.visit(node.value)
return ret_value
def visit_Constant(self, node: ast.Constant):
return R.emit(rx.const(node.value))
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def _binOp_maker(self, node: ast.operator):
if isinstance(node, ast.Add):
return R.add
else:
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
@jit(target="cpu")
def add():
out = 1 + 1
return out
add()
相比`06.py`,我们这里做了不少新的,具体的事。如上文所述,这里我们开始做更实际的加法,于是我们修改了我们的`add`函数。针对我们新的变化,我们引入了一些新的概念与实现,如上文所述,我们引入了一个`Symbol Table: self.local_var_table`用来追踪变量,这里我们实现非常的简单,仅仅是一个`Dictionary`,并且没有考虑`scope`,但是对于我们这里的问题已经足够。这里针对变量,在Python的AST中为`Name`,所以我们`Symbol Table`也主要在`Visit_Name`进行相关的读取操作,我们也看到了我们将其翻译为了`Relax Var`,在进行`Assign`操作完毕后,我们将生成好的`value`与我们`Symbol Table`对应的`name`进行映射。这里的核心则在于了我们的`Op`操作,即`Add`,我们在`visit_BinOp`进行了处理,逻辑很简单,拿左右两个操作数,即这里的数字`1`,进行相应的翻译(即`visit_Constant`),然后调用了`_binOp_maker`进行处理,而这里的`_binOp_maker`其实仅仅是调用了我们`Relax`的内置函数`add`,就这样完成了相应的翻译。我们运行程序可以看到如下输出:
...
Visit Module
Visit FunctionDef
Visit Assign
Visit Name
Visit BinOp
Visit Constant
Visit Constant
Visit Return
Visit Name
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def add() -> R.Tensor((), dtype="int32"):
gv: R.Tensor((), dtype="int32") = R.const(1, "int32")
gv1: R.Tensor((), dtype="int32") = R.const(1, "int32")
out: R.Tensor((), dtype="int32") = R.add(gv, gv1)
return out
可以看到已经有点像模像样了。那么我们试着加一点代码,让它运行起来,达成一个阶段性的小目标。
08.py
import inspect
import ast
from typing import Dict, Any
import tvm
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
code_generator = CodeGenerator(fn_ast, self.target)
compiled_kernel = code_generator.code_gen()
return compiled_kernel()
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, target):
self.fn_ast = fn_ast
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
self.local_var_table : Dict[str, Any] = {}
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
mapped_target = {'cpu': 'llvm', 'gpu': 'cuda'}
target = tvm.target.Target(mapped_target[self.target])
with tvm.transform.PassContext(opt_level=3):
ex = rx.build(module, target=target)
device = tvm.cuda() if "cuda" in target.keys else tvm.cpu()
vm = rx.VirtualMachine(ex, device=device)
return vm[self.entry]
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_Pass(self, node: ast.Pass):
pass
def visit_Assign(self, node: ast.Assign):
if len(node.targets) != 1:
raise NotImplementedError("Doesn't support simultaneous multiple assignment like 'a = b = c' in AST node type: {}".format(type(node).__name__))
target: rx.Var = self.visit(node.targets[0])
value = self.visit(node.value)
self.local_var_table[target.name_hint] = value
self.ib.name(target.name_hint, value)
def visit_Name(self, node: ast.Name):
name = node.id
if isinstance(node.ctx, ast.Store):
if name not in self.local_var_table.keys():
self.local_var_table[name] = rx.Var(name, struct_info=rx.ObjectStructInfo())
return self.local_var_table[name]
def visit_BinOp(self, node: ast.BinOp):
lhs = self.visit(node.left)
rhs = self.visit(node.right)
return R.emit(self._binOp_maker(node.op)(lhs, rhs))
def visit_Return(self, node: ast.Return):
ret_value = self.visit(node.value)
return ret_value
def visit_Constant(self, node: ast.Constant):
return R.emit(rx.const(node.value))
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def _binOp_maker(self, node: ast.operator):
if isinstance(node, ast.Add):
return R.add
else:
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
@jit(target="cpu")
def add():
out = 1 + 1
return out
print(add())
在这里,我们添加了 print(add()) 来尝试打印我们编译好的 Kernel 结果。在这里我们改动的地方主要在`code_gen`函数,其主要逻辑就是使用`build`我们创建好的 IRModule 变为 VMExecutable ,然后传递给 Relax Virtual Machine 可以执行。这里我们也将调用的地方也进行了必要的修改,即我们返回了 compiled_kernel() 。如果我们运行程序,我们可以得到如下的输出:
...
Visit Return
Visit Name
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def add() -> R.Tensor((), dtype="int32"):
gv: R.Tensor((), dtype="int32") = R.const(1, "int32")
gv1: R.Tensor((), dtype="int32") = R.const(1, "int32")
out: R.Tensor((), dtype="int32") = R.add(gv, gv1)
return out
2
可以看到这个结果是正确的。说明完成了一小步。我知道有心急的小伙伴,可能这时候想尝试 gpu target ,不过很遗憾,需要再忍耐一下,现在直接修改会报错,先一步一步来。现在让我们做点更有趣的事情,我们来加一个 Pass ,看看 R.add 里面到底是什么。
09.py
import inspect
import ast
from typing import Dict, Any
import tvm
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
code_generator = CodeGenerator(fn_ast, self.target)
compiled_kernel = code_generator.code_gen()
return compiled_kernel()
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, target):
self.fn_ast = fn_ast
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
self.local_var_table : Dict[str, Any] = {}
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
# apply transform pass on module
with tvm.transform.PassContext(opt_level=3):
# Apply Opt Pass
seq = tvm.transform.Sequential(
[
rx.transform.LegalizeOps(),
])
module = seq(module)
print("After applied passes...")
print(module)
mapped_target = {'cpu': 'llvm', 'gpu': 'cuda'}
target = tvm.target.Target(mapped_target[self.target])
with tvm.transform.PassContext(opt_level=3):
ex = rx.build(module, target=target)
device = tvm.cuda() if "cuda" in target.keys else tvm.cpu()
vm = rx.VirtualMachine(ex, device=device)
return vm[self.entry]
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_Pass(self, node: ast.Pass):
pass
def visit_Assign(self, node: ast.Assign):
if len(node.targets) != 1:
raise NotImplementedError("Doesn't support simultaneous multiple assignment like 'a = b = c' in AST node type: {}".format(type(node).__name__))
target: rx.Var = self.visit(node.targets[0])
value = self.visit(node.value)
self.local_var_table[target.name_hint] = value
self.ib.name(target.name_hint, value)
def visit_Name(self, node: ast.Name):
name = node.id
if isinstance(node.ctx, ast.Store):
if name not in self.local_var_table.keys():
self.local_var_table[name] = rx.Var(name, struct_info=rx.ObjectStructInfo())
return self.local_var_table[name]
def visit_BinOp(self, node: ast.BinOp):
lhs = self.visit(node.left)
rhs = self.visit(node.right)
return R.emit(self._binOp_maker(node.op)(lhs, rhs))
def visit_Return(self, node: ast.Return):
ret_value = self.visit(node.value)
return ret_value
def visit_Constant(self, node: ast.Constant):
return R.emit(rx.const(node.value))
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def _binOp_maker(self, node: ast.operator):
if isinstance(node, ast.Add):
return R.add
else:
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
@jit(target="cpu")
def add():
out = 1 + 1
return out
print(add())
其实这里就仅仅是添加了一个 LegalizeOps 的 Pass 来达到这一点,我们这里使用了 Sequential 来包裹我们的 Pass ,因为我们后面还会加入更多的 Pass 来做我们想要做的一些事情。运行我们的程序我们可以得到类似的输出:
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def add() -> R.Tensor((), dtype="int32"):
gv: R.Tensor((), dtype="int32") = R.const(1, "int32")
gv1: R.Tensor((), dtype="int32") = R.const(1, "int32")
out: R.Tensor((), dtype="int32") = R.add(gv, gv1)
return out
After applied passes...
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func(private=True)
def add1(gv: T.Buffer((), "int32"), gv1: T.Buffer((), "int32"), T_add: T.Buffer((), "int32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
with T.block("T_add"):
vi = T.axis.spatial(1, T.int64(0))
T.reads(gv[()], gv1[()])
T.writes(T_add[()])
T_add[()] = gv[()] + gv1[()]
@R.function
def add() -> R.Tensor((), dtype="int32"):
cls = Module
gv: R.Tensor((), dtype="int32") = R.const(1, "int32")
gv1: R.Tensor((), dtype="int32") = R.const(1, "int32")
out = R.call_tir(cls.add1, (gv, gv1), out_sinfo=R.Tensor((), dtype="int32"))
return out
我们可以发现,其实 R.add 底层的 TensorIR 表示是这样的:
@T.prim_func(private=True)
def add1(gv: T.Buffer((), "int32"), gv1: T.Buffer((), "int32"), T_add: T.Buffer((), "int32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
with T.block("T_add"):
vi = T.axis.spatial(1, T.int64(0))
T.reads(gv[()], gv1[()])
T.writes(T_add[()])
T_add[()] = gv[()] + gv1[()]
接下来,我们做一下跟深度学习结合更紧密的事情,那就是我们让我们的加法支持张量的运算,并且我们允许我们的张量的值可以直接从Torch进行传递,这也是我们这个 compiler 的核心意义体现。那么对于张量,我们其最关键的属性,其实就三个, shape,dtype, data ,体现张量的维度、类型以及值,而这里唯一需要考虑的是如何存储 data ?那么TVM里面则是使用了 ndarray 来进行表示。那么 ndarray 如何从Torch里面高效的拿值?那么这里就需要感谢[DLPack](Welcome to DLPack’s documentation!),它可以用于跨框架的多维数据的交互。那么我们的张量定义就很简单了:
class Tensor:
def __init__(self, shape, dtype):
self.shape = shape
self.dtype = dtype
self._data = None
@property
def data(self):
return self._data
@data.setter
def data(self, data: "torch.Tensor"):
def _from_dlpack(tensor):
from tvm.runtime import Device
from tvm.runtime import ndarray
try:
return ndarray.from_dlpack(tensor)
except RuntimeError:
pass
device_type = tensor.device.type
device_id = tensor.device.index or 0
return ndarray.array(
tensor.numpy(),
device=Device(
Device.STR2MASK[device_type],
device_id,
),
)
data = _from_dlpack(data)
if data.shape != tuple(self.shape):
raise ValueError(f"Shape mismatch: expected {tuple(self.shape)}, got {data.shape}")
if data.dtype != self.dtype:
raise ValueError(f"Dtype mismatch: expected {self.dtype}, got {data.dtype}")
self._data = data
def __str__(self):
return str(self.dtype) + '[' + ', '.join(str(s) for s in self.shape) + ']'
其使用方法很简单
a = Tensor(shape=(2, 3), dtype="float32")
a.data = torch.ones(size=(2, 3), dtype=torch.float32)
print(a)
print(a.data)
print(type(a.data))
这里我省略了一些包的导入,我相信大家可以解决这个简单的问题。那么运行以后可以得到:
float32[2, 3]
[[1. 1. 1.]
[1. 1. 1.]]
<class 'tvm.runtime.ndarray.NDArray'>
那么接下来,我们要做更有趣的事情了,那就是把这个 Tensor 作为参数传递给我们的 add ,即变为:
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
out = a + b
return out
来运行张量的运算,那么我们接下来需要添加函数参数的支持、 Tensor 到 Relax 的翻译等,其实实现也不复杂:
10.py
import inspect
import ast
import astunparse
from typing import Dict, Any
import torch
import tvm
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
ctx = self.fn.__globals__.copy()
code_generator = CodeGenerator(fn_ast, ctx, self.target)
compiled_kernel = code_generator.code_gen()
input_args = []
for arg in args:
input_args.append(arg.data)
return compiled_kernel(*input_args)
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, ctx, target):
self.fn_ast = fn_ast
self.ctx = ctx
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
self.local_var_table : Dict[str, Any] = {}
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
# apply transform pass on module
with tvm.transform.PassContext(opt_level=3):
# Apply Opt Pass
seq = tvm.transform.Sequential(
[
rx.transform.LegalizeOps(),
])
module = seq(module)
print("After applied passes...")
print(module)
mapped_target = {'cpu': 'llvm', 'gpu': 'cuda'}
target = tvm.target.Target(mapped_target[self.target])
with tvm.transform.PassContext(opt_level=3):
ex = rx.build(module, target=target)
device = tvm.cuda() if "cuda" in target.keys else tvm.cpu()
vm = rx.VirtualMachine(ex, device=device)
return vm[self.entry]
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self.visit(node.args)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_arguments(self, node: ast.arguments):
for arg in node.args:
if arg.annotation is None:
raise ValueError(arg, "Type annotation is required for function parameters.")
arg_name = arg.arg
anno = eval(astunparse.unparse(arg.annotation), self.ctx)
param = R.arg(arg_name, R.Tensor(shape=anno.shape, dtype=anno.dtype))
self.local_var_table[arg_name] = param
def visit_Pass(self, node: ast.Pass):
pass
def visit_Assign(self, node: ast.Assign):
if len(node.targets) != 1:
raise NotImplementedError("Doesn't support simultaneous multiple assignment like 'a = b = c' in AST node type: {}".format(type(node).__name__))
target: rx.Var = self.visit(node.targets[0])
value = self.visit(node.value)
self.local_var_table[target.name_hint] = value
self.ib.name(target.name_hint, value)
def visit_Name(self, node: ast.Name):
name = node.id
if isinstance(node.ctx, ast.Store):
if name not in self.local_var_table.keys():
self.local_var_table[name] = rx.Var(name, struct_info=rx.ObjectStructInfo())
return self.local_var_table[name]
def visit_BinOp(self, node: ast.BinOp):
lhs = self.visit(node.left)
rhs = self.visit(node.right)
return R.emit(self._binOp_maker(node.op)(lhs, rhs))
def visit_Return(self, node: ast.Return):
ret_value = self.visit(node.value)
return ret_value
def visit_Constant(self, node: ast.Constant):
return R.emit(rx.const(node.value))
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def _binOp_maker(self, node: ast.operator):
if isinstance(node, ast.Add):
return R.add
else:
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
class Tensor:
def __init__(self, shape, dtype):
self.shape = shape
self.dtype = dtype
self._data = None
@property
def data(self):
return self._data
@data.setter
def data(self, data: "torch.Tensor"):
def _from_dlpack(tensor):
from tvm.runtime import Device
from tvm.runtime import ndarray
try:
return ndarray.from_dlpack(tensor)
except RuntimeError:
pass
device_type = tensor.device.type
device_id = tensor.device.index or 0
return ndarray.array(
tensor.numpy(),
device=Device(
Device.STR2MASK[device_type],
device_id,
),
)
data = _from_dlpack(data)
if data.shape != tuple(self.shape):
raise ValueError(f"Shape mismatch: expected {tuple(self.shape)}, got {data.shape}")
if data.dtype != self.dtype:
raise ValueError(f"Dtype mismatch: expected {self.dtype}, got {data.dtype}")
self._data = data
def __str__(self):
return str(self.dtype) + '[' + ', '.join(str(s) for s in self.shape) + ']'
@jit(target="cpu")
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
out = a + b
return out
a = Tensor(shape=(2, 3), dtype="float32")
b = Tensor(shape=(2, 3), dtype="float32")
a.data = torch.ones(size=(2, 3), dtype=torch.float32)
b.data = torch.ones(size=(2, 3), dtype=torch.float32)
print(add(a, b))
在这里,我们做了一些必要的支持。首先是 visit_arguments ,这是处理包含 Tensor 类型参数的地方,这里可以看到,我们其实本质是翻译为了对应的 R.Tensor ,shape / dtype都取自于这里的 Tensor 类。当然为了更方便的获得,我们使用了一个小技巧,使用 eval 和 astunparse 来取得了我们想要的东西。这里有可能会问,如果是动态的怎么办?那么Relax有 DynTensorType 可以比较方便的支持。最后,我们在调用的地方,也简化了问题,我们认为 args 一定是 Tensor 类,所以我们直接取了 arg.data ,然后传递给了我们的Kernel,如果运行的话,我们可以看到如下的结果:
...
After applied passes...
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func(private=True)
def add1(a: T.Buffer((T.int64(2), T.int64(3)), "float32"), b: T.Buffer((T.int64(2), T.int64(3)), "float32"), T_add: T.Buffer((T.int64(2), T.int64(3)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(2), T.int64(3)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(a[v_ax0, v_ax1], b[v_ax0, v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = a[v_ax0, v_ax1] + b[v_ax0, v_ax1]
@R.function
def add(a: R.Tensor((2, 3), dtype="float32"), b: R.Tensor((2, 3), dtype="float32")) -> R.Tensor((2, 3), dtype="float32"):
cls = Module
out = R.call_tir(cls.add1, (a, b), out_sinfo=R.Tensor((2, 3), dtype="float32"))
return out
[[2. 2. 2.]
[2. 2. 2.]]
这里我们可以观察到了,有了一点深度学习的意味了,TensorIR也开始引入了 loop ,既然现在有了张量,那么现在我们可以做一下刚才提到的有趣的事情了,那就是我们添加一下GPU的运行支持。由于GPU的Kernel你需要进行`block`/ thread 等信息的绑定,所以直接运行会有问题。那么如何使其可以支持,这里其实可以有几种做法,一种当然是手动来,如[mlc-ai文章](mlc.ai/zh/chapter_gpu_a)提到的一样,但是另外的方式就是更自动化一点,如[Meta Schedule](tvm-rfcs/rfcs/0005-meta-schedule-autotensorir.md at main · apache/tvm-rfcs),相比 Meta Schedule 更轻量化的[Dlight](github.com/apache/tvm/p),这里我们就用 Dlight 来完成我们的目的。
11.py
import inspect
import ast
import astunparse
from typing import Dict, Any
import torch
import tvm
from tvm import dlight as dl
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
ctx = self.fn.__globals__.copy()
code_generator = CodeGenerator(fn_ast, ctx, self.target)
compiled_kernel = code_generator.code_gen()
input_args = []
for arg in args:
input_args.append(arg.data)
return compiled_kernel(*input_args)
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, ctx, target):
self.fn_ast = fn_ast
self.ctx = ctx
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
self.local_var_table : Dict[str, Any] = {}
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
# apply transform pass on module
with tvm.transform.PassContext(opt_level=3):
# Apply Opt Pass
seq = tvm.transform.Sequential(
[
rx.transform.LegalizeOps(),
])
module = seq(module)
print("After applied passes...")
print(module)
mapped_target = {'cpu': 'llvm', 'gpu': 'cuda'}
target = tvm.target.Target(mapped_target[self.target])
if "cuda" in target.keys:
with target:
module = dl.ApplyDefaultSchedule(dl.gpu.Fallback(),)(module)
print("After applied dlight...")
print(module)
with tvm.transform.PassContext(opt_level=3):
ex = rx.build(module, target=target)
device = tvm.cuda() if "cuda" in target.keys else tvm.cpu()
vm = rx.VirtualMachine(ex, device=device)
return vm[self.entry]
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self.visit(node.args)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_arguments(self, node: ast.arguments):
for arg in node.args:
if arg.annotation is None:
raise ValueError(arg, "Type annotation is required for function parameters.")
arg_name = arg.arg
anno = eval(astunparse.unparse(arg.annotation), self.ctx)
param = R.arg(arg_name, R.Tensor(shape=anno.shape, dtype=anno.dtype))
self.local_var_table[arg_name] = param
def visit_Pass(self, node: ast.Pass):
pass
def visit_Assign(self, node: ast.Assign):
if len(node.targets) != 1:
raise NotImplementedError("Doesn't support simultaneous multiple assignment like 'a = b = c' in AST node type: {}".format(type(node).__name__))
target: rx.Var = self.visit(node.targets[0])
value = self.visit(node.value)
self.local_var_table[target.name_hint] = value
self.ib.name(target.name_hint, value)
def visit_Name(self, node: ast.Name):
name = node.id
if isinstance(node.ctx, ast.Store):
if name not in self.local_var_table.keys():
self.local_var_table[name] = rx.Var(name, struct_info=rx.ObjectStructInfo())
return self.local_var_table[name]
def visit_BinOp(self, node: ast.BinOp):
lhs = self.visit(node.left)
rhs = self.visit(node.right)
return R.emit(self._binOp_maker(node.op)(lhs, rhs))
def visit_Return(self, node: ast.Return):
ret_value = self.visit(node.value)
return ret_value
def visit_Constant(self, node: ast.Constant):
return R.emit(rx.const(node.value))
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def _binOp_maker(self, node: ast.operator):
if isinstance(node, ast.Add):
return R.add
else:
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
class Tensor:
def __init__(self, shape, dtype):
self.shape = shape
self.dtype = dtype
self._data = None
@property
def data(self):
return self._data
@data.setter
def data(self, data: "torch.Tensor"):
def _from_dlpack(tensor):
from tvm.runtime import Device
from tvm.runtime import ndarray
try:
return ndarray.from_dlpack(tensor)
except RuntimeError:
pass
device_type = tensor.device.type
device_id = tensor.device.index or 0
return ndarray.array(
tensor.numpy(),
device=Device(
Device.STR2MASK[device_type],
device_id,
),
)
data = _from_dlpack(data)
if data.shape != tuple(self.shape):
raise ValueError(f"Shape mismatch: expected {tuple(self.shape)}, got {data.shape}")
if data.dtype != self.dtype:
raise ValueError(f"Dtype mismatch: expected {self.dtype}, got {data.dtype}")
self._data = data
def __str__(self):
return str(self.dtype) + '[' + ', '.join(str(s) for s in self.shape) + ']'
@jit(target="gpu")
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
out = a + b
return out
a = Tensor(shape=(2, 3), dtype="float32")
b = Tensor(shape=(2, 3), dtype="float32")
a.data = torch.ones(size=(2, 3), dtype=torch.float32, device="cuda")
b.data = torch.ones(size=(2, 3), dtype=torch.float32, device="cuda")
print(add(a, b))
在这里,我们添加了相应的 Dlight 支持,现在我们可以运行支持GPU的代码了,其实核心就一条
module = dl.ApplyDefaultSchedule(dl.gpu.Fallback(),)(module)
当然这里也需要注意,我们torch的tensor需要变为GPU的设备。
运行结果如下:
After applied dlight...
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func(private=True)
def add1(a: T.Buffer((T.int64(2), T.int64(3)), "float32"), b: T.Buffer((T.int64(2), T.int64(3)), "float32"), T_add: T.Buffer((T.int64(2), T.int64(3)), "float32")):
T.func_attr({"tir.is_scheduled": 1, "tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0_ax1_fused_0 in T.thread_binding(T.int64(1), thread="blockIdx.x"):
for ax0_ax1_fused_1 in T.thread_binding(T.int64(1024), thread="threadIdx.x"):
with T.block("T_add"):
v0 = T.axis.spatial(T.int64(2), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) // T.int64(3))
v1 = T.axis.spatial(T.int64(3), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) % T.int64(3))
T.where(ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1 < T.int64(6))
T.reads(a[v0, v1], b[v0, v1])
T.writes(T_add[v0, v1])
T_add[v0, v1] = a[v0, v1] + b[v0, v1]
@R.function
def add(a: R.Tensor((2, 3), dtype="float32"), b: R.Tensor((2, 3), dtype="float32")) -> R.Tensor((2, 3), dtype="float32"):
cls = Module
out = R.call_tir(cls.add1, (a, b), out_sinfo=R.Tensor((2, 3), dtype="float32"))
return out
[[2. 2. 2.]
[2. 2. 2.]]
可以看到,我们的IR也有一些变化,开始出现了 threadIdx.x 等东西。那么,接下来,我们开始添加代码,回应我们最开始提到的目的,那就是针对GPU,我们还希望打印CUDA代码。我们只需要这样做就可以了,核心就一句:
print(ex.mod.imported_modules[0].imported_modules[0].get_source())
12.py
import inspect
import ast
import astunparse
from typing import Dict, Any
import torch
import tvm
from tvm import dlight as dl
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
ctx = self.fn.__globals__.copy()
code_generator = CodeGenerator(fn_ast, ctx, self.target)
compiled_kernel = code_generator.code_gen()
input_args = []
for arg in args:
input_args.append(arg.data)
return compiled_kernel(*input_args)
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, ctx, target):
self.fn_ast = fn_ast
self.ctx = ctx
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
self.local_var_table : Dict[str, Any] = {}
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
# apply transform pass on module
with tvm.transform.PassContext(opt_level=3):
# Apply Opt Pass
seq = tvm.transform.Sequential(
[
rx.transform.LegalizeOps(),
])
module = seq(module)
print("After applied passes...")
print(module)
mapped_target = {'cpu': 'llvm', 'gpu': 'cuda'}
target = tvm.target.Target(mapped_target[self.target])
if "cuda" in target.keys:
with target:
module = dl.ApplyDefaultSchedule(dl.gpu.Fallback(),)(module)
print("After applied dlight...")
print(module)
with tvm.transform.PassContext(opt_level=3):
ex = rx.build(module, target=target)
if "cuda" in target.keys:
# dump cuda source
print(ex.mod.imported_modules[0].imported_modules[0].get_source())
device = tvm.cuda() if "cuda" in target.keys else tvm.cpu()
vm = rx.VirtualMachine(ex, device=device)
return vm[self.entry]
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self.visit(node.args)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_arguments(self, node: ast.arguments):
for arg in node.args:
if arg.annotation is None:
raise ValueError(arg, "Type annotation is required for function parameters.")
arg_name = arg.arg
anno = eval(astunparse.unparse(arg.annotation), self.ctx)
param = R.arg(arg_name, R.Tensor(shape=anno.shape, dtype=anno.dtype))
self.local_var_table[arg_name] = param
def visit_Pass(self, node: ast.Pass):
pass
def visit_Assign(self, node: ast.Assign):
if len(node.targets) != 1:
raise NotImplementedError("Doesn't support simultaneous multiple assignment like 'a = b = c' in AST node type: {}".format(type(node).__name__))
target: rx.Var = self.visit(node.targets[0])
value = self.visit(node.value)
self.local_var_table[target.name_hint] = value
self.ib.name(target.name_hint, value)
def visit_Name(self, node: ast.Name):
name = node.id
if isinstance(node.ctx, ast.Store):
if name not in self.local_var_table.keys():
self.local_var_table[name] = rx.Var(name, struct_info=rx.ObjectStructInfo())
return self.local_var_table[name]
def visit_BinOp(self, node: ast.BinOp):
lhs = self.visit(node.left)
rhs = self.visit(node.right)
return R.emit(self._binOp_maker(node.op)(lhs, rhs))
def visit_Return(self, node: ast.Return):
ret_value = self.visit(node.value)
return ret_value
def visit_Constant(self, node: ast.Constant):
return R.emit(rx.const(node.value))
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def _binOp_maker(self, node: ast.operator):
if isinstance(node, ast.Add):
return R.add
else:
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
class Tensor:
def __init__(self, shape, dtype):
self.shape = shape
self.dtype = dtype
self._data = None
@property
def data(self):
return self._data
@data.setter
def data(self, data: "torch.Tensor"):
def _from_dlpack(tensor):
from tvm.runtime import Device
from tvm.runtime import ndarray
try:
return ndarray.from_dlpack(tensor)
except RuntimeError:
pass
device_type = tensor.device.type
device_id = tensor.device.index or 0
return ndarray.array(
tensor.numpy(),
device=Device(
Device.STR2MASK[device_type],
device_id,
),
)
data = _from_dlpack(data)
if data.shape != tuple(self.shape):
raise ValueError(f"Shape mismatch: expected {tuple(self.shape)}, got {data.shape}")
if data.dtype != self.dtype:
raise ValueError(f"Dtype mismatch: expected {self.dtype}, got {data.dtype}")
self._data = data
def __str__(self):
return str(self.dtype) + '[' + ', '.join(str(s) for s in self.shape) + ']'
@jit(target="gpu")
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
out = a + b
return out
a = Tensor(shape=(2, 3), dtype="float32")
b = Tensor(shape=(2, 3), dtype="float32")
a.data = torch.ones(size=(2, 3), dtype=torch.float32, device="cuda")
b.data = torch.ones(size=(2, 3), dtype=torch.float32, device="cuda")
print(add(a, b))
运行后结果:
...
#if (((__CUDACC_VER_MAJOR__ == 11) && (__CUDACC_VER_MINOR__ >= 4)) || \
(__CUDACC_VER_MAJOR__ > 11))
#define TVM_ENABLE_L2_PREFETCH 1
#else
#define TVM_ENABLE_L2_PREFETCH 0
#endif
#ifdef _WIN32
using uint = unsigned int;
using uchar = unsigned char;
using ushort = unsigned short;
using int64_t = long long;
using uint64_t = unsigned long long;
#else
#define uint unsigned int
#define uchar unsigned char
#define ushort unsigned short
#define int64_t long long
#define uint64_t unsigned long long
#endif
extern "C" __global__ void __launch_bounds__(1024) add1_kernel(float* __restrict__ T_add, float* __restrict__ a, float* __restrict__ b);
extern "C" __global__ void __launch_bounds__(1024) add1_kernel(float* __restrict__ T_add, float* __restrict__ a, float* __restrict__ b) {
if (((int)threadIdx.x) < 6) {
T_add[((int)threadIdx.x)] = (a[((int)threadIdx.x)] + b[((int)threadIdx.x)]);
}
}到这一步,我们基本上完成了我们之前提到的一些点,但是在收尾前,我们再做一点有趣的事,那就是支持融合,毕竟之前`Sequential`已经留好了位置了。首先,我们将 add 代码变为两个加法的操作,即
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
out = a + b
out = out + a
return out
然后我们只需要变为一系列 Pass 即可完成这样的操作
rx.transform.ConvertToDataflow(),
rx.transform.LegalizeOps(),
rx.transform.AnnotateTIROpPattern(),
rx.transform.FuseOps(),
rx.transform.FuseTIR(),
这里其实稍微需要注意的是 ConvertToDataflow ,它会将我们函数中,没有 SideEffect 的操作融合在一个 Dataflow 中(如没有I/O操作,If/Else等Control flow),这是进行算子融合必要的动作。
13.py
import inspect
import ast
import astunparse
from typing import Dict, Any
import torch
import tvm
from tvm import dlight as dl
from tvm import relax as rx
from tvm.script import relax as R
from tvm.script.ir_builder import relax as relax_builder, ir as I, IRBuilder as IB
def jit(target="cpu"):
assert target in ["cpu", "gpu"]
def inner(fn):
return JIT(fn, target=target)
return inner
class JIT:
def __init__(self, fn, target="cpu"):
self.fn = fn
self.target = target
def __call__(self, *args, **kwargs):
fn_src = inspect.getsource(self.fn)
fn_ast = ast.parse(fn_src)
print(ast.dump(fn_ast))
ctx = self.fn.__globals__.copy()
code_generator = CodeGenerator(fn_ast, ctx, self.target)
compiled_kernel = code_generator.code_gen()
input_args = []
for arg in args:
input_args.append(arg.data)
return compiled_kernel(*input_args)
class CodeGenerator(ast.NodeVisitor):
def __init__(self, fn_ast, ctx, target):
self.fn_ast = fn_ast
self.ctx = ctx
self.target = target
self.ib = IB()
self.ir_module = None
self.entry = None
self.ret = None
self.local_var_table : Dict[str, Any] = {}
def code_gen(self):
with self.ib:
self.visit(self.fn_ast)
module = self.ib.get()
print(module)
# apply transform pass on module
with tvm.transform.PassContext(opt_level=3):
# Apply Opt Pass
seq = tvm.transform.Sequential(
[
rx.transform.ConvertToDataflow(),
rx.transform.LegalizeOps(),
rx.transform.AnnotateTIROpPattern(),
rx.transform.FuseOps(),
rx.transform.FuseTIR(),
])
module = seq(module)
print("After applied passes...")
print(module)
mapped_target = {'cpu': 'llvm', 'gpu': 'cuda'}
target = tvm.target.Target(mapped_target[self.target])
if "cuda" in target.keys:
with target:
module = dl.ApplyDefaultSchedule(dl.gpu.Fallback(),)(module)
print("After applied dlight...")
print(module)
with tvm.transform.PassContext(opt_level=3):
ex = rx.build(module, target=target)
if "cuda" in target.keys:
# dump cuda source
print(ex.mod.imported_modules[0].imported_modules[0].get_source())
device = tvm.cuda() if "cuda" in target.keys else tvm.cpu()
vm = rx.VirtualMachine(ex, device=device)
return vm[self.entry]
def visit(self, node):
print("Visit " + node.__class__.__name__)
return super().visit(node)
def visit_Module(self, node: ast.Module):
if self.ir_module:
raise AssertionError("We should have only one module!")
self.ir_module = I.ir_module()
with self.ir_module:
super().generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
fn = relax_builder.function()
self.entry = node.name
with fn:
R.func_name(node.name)
self.visit(node.args)
self._visit_compound_stmt(node.body)
if self.ret is None:
R.func_ret_value(rx.ShapeExpr([]))
else:
R.func_ret_value(self.ret)
def visit_arguments(self, node: ast.arguments):
for arg in node.args:
if arg.annotation is None:
raise ValueError(arg, "Type annotation is required for function parameters.")
arg_name = arg.arg
anno = eval(astunparse.unparse(arg.annotation), self.ctx)
param = R.arg(arg_name, R.Tensor(shape=anno.shape, dtype=anno.dtype))
self.local_var_table[arg_name] = param
def visit_Pass(self, node: ast.Pass):
pass
def visit_Assign(self, node: ast.Assign):
if len(node.targets) != 1:
raise NotImplementedError("Doesn't support simultaneous multiple assignment like 'a = b = c' in AST node type: {}".format(type(node).__name__))
target: rx.Var = self.visit(node.targets[0])
value = self.visit(node.value)
self.local_var_table[target.name_hint] = value
self.ib.name(target.name_hint, value)
def visit_Name(self, node: ast.Name):
name = node.id
if isinstance(node.ctx, ast.Store):
if name not in self.local_var_table.keys():
self.local_var_table[name] = rx.Var(name, struct_info=rx.ObjectStructInfo())
return self.local_var_table[name]
def visit_BinOp(self, node: ast.BinOp):
lhs = self.visit(node.left)
rhs = self.visit(node.right)
return R.emit(self._binOp_maker(node.op)(lhs, rhs))
def visit_Return(self, node: ast.Return):
ret_value = self.visit(node.value)
return ret_value
def visit_Constant(self, node: ast.Constant):
return R.emit(rx.const(node.value))
def _visit_compound_stmt(self, stmts):
assert isinstance(stmts, (list, tuple))
for stmt in stmts:
ret = self.visit(stmt)
if ret is not None and isinstance(stmt, ast.Return):
self.ret = ret
def _binOp_maker(self, node: ast.operator):
if isinstance(node, ast.Add):
return R.add
else:
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
def generic_visit(self, node: ast.AST):
raise NotImplementedError("Unsupported AST node type: {}".format(type(node).__name__))
class Tensor:
def __init__(self, shape, dtype):
self.shape = shape
self.dtype = dtype
self._data = None
@property
def data(self):
return self._data
@data.setter
def data(self, data: "torch.Tensor"):
def _from_dlpack(tensor):
from tvm.runtime import Device
from tvm.runtime import ndarray
try:
return ndarray.from_dlpack(tensor)
except RuntimeError:
pass
device_type = tensor.device.type
device_id = tensor.device.index or 0
return ndarray.array(
tensor.numpy(),
device=Device(
Device.STR2MASK[device_type],
device_id,
),
)
data = _from_dlpack(data)
if data.shape != tuple(self.shape):
raise ValueError(f"Shape mismatch: expected {tuple(self.shape)}, got {data.shape}")
if data.dtype != self.dtype:
raise ValueError(f"Dtype mismatch: expected {self.dtype}, got {data.dtype}")
self._data = data
def __str__(self):
return str(self.dtype) + '[' + ', '.join(str(s) for s in self.shape) + ']'
@jit(target="gpu")
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
out = a + b
out = out + a
return out
a = Tensor(shape=(2, 3), dtype="float32")
b = Tensor(shape=(2, 3), dtype="float32")
a.data = torch.ones(size=(2, 3), dtype=torch.float32, device="cuda")
b.data = torch.ones(size=(2, 3), dtype=torch.float32, device="cuda")
print(add(a, b))
运行后:
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def add(a: R.Tensor((2, 3), dtype="float32"), b: R.Tensor((2, 3), dtype="float32")) -> R.Tensor((2, 3), dtype="float32"):
out: R.Tensor((2, 3), dtype="float32") = R.add(a, b)
out_1: R.Tensor((2, 3), dtype="float32") = R.add(out, a)
return out_1
After applied passes...
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func(private=True)
def fused_add1_add1(a: T.Buffer((T.int64(2), T.int64(3)), "float32"), b: T.Buffer((T.int64(2), T.int64(3)), "float32"), T_add_intermediate_1: T.Buffer((T.int64(2), T.int64(3)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
T_add_intermediate = T.alloc_buffer((T.int64(2), T.int64(3)))
for ax0, ax1 in T.grid(T.int64(2), T.int64(3)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(a[v_ax0, v_ax1], b[v_ax0, v_ax1])
T.writes(T_add_intermediate[v_ax0, v_ax1])
T_add_intermediate[v_ax0, v_ax1] = a[v_ax0, v_ax1] + b[v_ax0, v_ax1]
for ax0, ax1 in T.grid(T.int64(2), T.int64(3)):
with T.block("T_add_1"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(T_add_intermediate[v_ax0, v_ax1], a[v_ax0, v_ax1])
T.writes(T_add_intermediate_1[v_ax0, v_ax1])
T_add_intermediate_1[v_ax0, v_ax1] = T_add_intermediate[v_ax0, v_ax1] + a[v_ax0, v_ax1]
@R.function
def add(a: R.Tensor((2, 3), dtype="float32"), b: R.Tensor((2, 3), dtype="float32")) -> R.Tensor((2, 3), dtype="float32"):
cls = Module
with R.dataflow():
gv = R.call_tir(cls.fused_add1_add1, (a, b), out_sinfo=R.Tensor((2, 3), dtype="float32"))
R.output(gv)
return gv
After applied dlight...
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func(private=True)
def fused_add1_add1(a: T.Buffer((T.int64(2), T.int64(3)), "float32"), b: T.Buffer((T.int64(2), T.int64(3)), "float32"), T_add_intermediate_1: T.Buffer((T.int64(2), T.int64(3)), "float32")):
T.func_attr({"tir.is_scheduled": 1, "tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0_ax1_fused_0 in T.thread_binding(T.int64(1), thread="blockIdx.x"):
for ax0_ax1_fused_1 in T.thread_binding(T.int64(1024), thread="threadIdx.x"):
with T.block("T_add_1"):
v0 = T.axis.spatial(T.int64(2), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) // T.int64(3))
v1 = T.axis.spatial(T.int64(3), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) % T.int64(3))
T.where(ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1 < T.int64(6))
T.reads(a[v0, v1], b[v0, v1])
T.writes(T_add_intermediate_1[v0, v1])
T_add_intermediate_1[v0, v1] = a[v0, v1] + b[v0, v1] + a[v0, v1]
@R.function
def add(a: R.Tensor((2, 3), dtype="float32"), b: R.Tensor((2, 3), dtype="float32")) -> R.Tensor((2, 3), dtype="float32"):
cls = Module
with R.dataflow():
gv = R.call_tir(cls.fused_add1_add1, (a, b), out_sinfo=R.Tensor((2, 3), dtype="float32"))
R.output(gv)
return gv
#if (((__CUDACC_VER_MAJOR__ == 11) && (__CUDACC_VER_MINOR__ >= 4)) || \
(__CUDACC_VER_MAJOR__ > 11))
#define TVM_ENABLE_L2_PREFETCH 1
#else
#define TVM_ENABLE_L2_PREFETCH 0
#endif
#ifdef _WIN32
using uint = unsigned int;
using uchar = unsigned char;
using ushort = unsigned short;
using int64_t = long long;
using uint64_t = unsigned long long;
#else
#define uint unsigned int
#define uchar unsigned char
#define ushort unsigned short
#define int64_t long long
#define uint64_t unsigned long long
#endif
extern "C" __global__ void __launch_bounds__(1024) fused_add1_add1_kernel(float* __restrict__ T_add, float* __restrict__ a, float* __restrict__ b);
extern "C" __global__ void __launch_bounds__(1024) fused_add1_add1_kernel(float* __restrict__ T_add, float* __restrict__ a, float* __restrict__ b) {
if (((int)threadIdx.x) < 6) {
T_add[((int)threadIdx.x)] = ((a[((int)threadIdx.x)] + b[((int)threadIdx.x)]) + a[((int)threadIdx.x)]);
}
}
[[3. 3. 3.]
[3. 3. 3.]]这里,我们有几点可以关注,一是我们有了如上文所述新的 R.dataflow ,同时我们可以观察到,我们两个 R.add 变为了一个融合算子 fused_add1_add1 ,这对于GPU是很关键的一个优化。
好了,我相信写到这里,基本上展示了一个Baby Triton的核心思想。那么接下来,如果感兴趣,可以继续做一些有趣的事情,我抛砖引玉一下:
1. 支持乘法操作 (难度:0.5颗星)
2. 将Dlight变为Meta Schedule,观察生成的IR和CUDA代码有何不同?(难度: 1颗星)
3. 支持If / Else control flow,并观察 dataflow 的插入位置有何不同(难度:2颗星)
- 需要注意Symbol Table,变量的作用域,需要
self.local_var_table进行必要的更改 - 是否可以完成没有Else的if语句支持(附加星:0.5颗星)
4. 支持For loops (难度2.5颗星),这里为了实现简单,可以考虑用递归方式实现
- 考虑在一个阈值内,Unroll Loop (附加难度0.5颗星)
5. 支持在用户代码中调用`Relax`库函数,如
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
out = a + b
out = sigmoid(out) #来自relax的sigmoid
return out
(难度: 2颗星)
6. 允许用户注册自己的TensorIR函数,嵌入到用户代码中,如:
@T.prim_func(private=True)
def custom_add(x: T.Buffer((T.int64(2), T.int64(3)), "float32"), y: T.Buffer((T.int64(2), T.int64(3)), "float32"), T_add: T.Buffer((T.int64(2), T.int64(3)), "float32")):
T.func_attr({"op_pattern": 0, "tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(2), T.int64(3)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(x[v_ax0, v_ax1], y[v_ax0, v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = x[v_ax0, v_ax1] + y[v_ax0, v_ax1]
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
sum = x + y
placeholder = sum
out = custom_add(x, sum, placeholder)
return out
难度(2颗星)
附加:能否支持不使用placeholder过渡?(附加难度星:0.5颗星)
7. 由于一些复杂的操作以及设备的多样性,一个算子内部的异构操作往往也有其必要性,我们如何支持异构操作?
def add(a: Tensor(shape=(2, 3), dtype="float32"), b: Tensor(shape=(2, 3), dtype="float32")):
with device("cpu):
sum = x + y
with device("gpu"):
out = sum + x
return out
难度(2.5颗星)
8. 我们目前选择了Relax作为我们的IR,我们是否可以选择 TensorIR 并实现为我们的 Code Generator? 难度(3颗星)
…
其实还有很多有趣的问题,大家可以尽情发挥你的创造力和想象力去实现它。
还没有人送礼物,鼓励一下作者吧

[
吴钊
C++等 4 个话题下的优秀答主
52 篇内容 · 12992 赞同
](https://zhuanlan.zhihu.com/frozengene)
[
最热内容 ·
深度学习推理引擎的一些思考
](https://zhuanlan.zhihu.com/frozengene)
发布于 2024-07-19 21:05・上海 ,编辑于 2024-07-22 09:16・上海编译