VeRL 是字节跳动seed团队和香港大学开发的强化学习仓库。该框架采用混合编程模型,融合单控制器(Single-Controller)的灵活性和多控制器(Multi-Controller)的高效性,可更好实现和执行多种RL算法,显著提升训练吞吐量,降低开发和维护复杂度。
相关资料
- VeRL框架的论文(HybridFlow): arxiv.org/pdf/2409.1925
- 论文解读: zhuanlan.zhihu.com/p/24
- VeRL框架的官方解读: mp.weixin.qq.com/s/JYQQ
- 仓库地址: github.com/volcengine/v
- Docs: Welcome to verl’s documentation!
- 知乎上的一些阅读笔记:
- zhuanlan.zhihu.com/p/26
1. RL(Post-Training)复杂计算流程给 LLM 训练带来全新的挑战
在 RLHF 中,需要同时训练多个模型,如 Actor 、Critic 、参考策略(Reference Policy)和奖励模型(Reward Model),并在它们之间传递大量数据。这些模型涉及不同的计算类型(前向反向传播、优化器更新、自回归生成等),可能采用不同的并行策略。
传统的分布式 RL 通常假设模型可在单个 GPU 上训练,或使用 数据并行方式 ,将控制流和计算流合并在同一进程中 。这在处理小规模模型时效果良好,但面对大模型,训练需要复杂的多维并行,涉及大量分布式计算,传统方法难以应对。
2. HybridFlow 解耦控制流和计算流,兼顾灵活高效
大模型 RL 本质上是一个二维的 DataFlow 问题:high-level 的 控制流 (描述 RL 算法的流程)+ low-level 的 计算流 (描述分布式神经网络计算)。
近期开源的 RLHF 框架,如 DeepSpeed-Chat 、OpenRLHF 和 NeMo-Aligner ,采用了统一的多控制器(Multi-Controller)架构。各计算节点独立管理计算和通信,降低了控制调度的开销。然而,控制流和计算流高度耦合,当设计新的 RL 算法,组合相同的计算流和不同的控制流时,需要重写计算流代码,修改所有相关模型,增加了开发难度。
与此前框架不同,HybridFlow 采用了混合编程模型,控制流由单控制器(Single-Controller)管理,具有全局视图,实现新的控制流简单快捷,计算流由多控制器(Multi-Controller)负责,保证了计算的高效执行,并且可以在不同的控制流中复用。
尽管相比纯粹的多控制器架构,这可能带来一定的控制调度开销,但 HybridFlow 通过优化数据传输,降低了控制流与计算流之间的传输量,兼顾了灵活性和高效性。
说明:
控制流:描述强化学习算法的逻辑流程。
计算流:模型计算的硬件执行过程。
耦合问题:控制流和计算混合
贡献点:解耦了控制流和计算流,控制流由单控制器(Single-Controller)管理,计算流由多控制器(Multi-Controller)负责。

3. 系统设计之一:Hybrid Programming Model (编程模型创新)
- 封装单模型分布式计算
在 HybridFlow 中,每个模型(如 Actor、Critic、参考策略、奖励模型等)的分布式计算被封装为独立的模块,称为 模型类 。
这些模型类继承于基础的并行 Worker 类(如 3DParallelWorker 、FSDPWorker 等),通过抽象的 API 接口,封装了模型的前向、反向计算、优化器更新和自回归生成等操作。该封装方式提高了代码的复用性,便于模型的维护和扩展。
对于不同的 RL 控制流,用户可以直接复用封装好的模型类,同时自定义部分算法所需的数值计算,实现不同算法。当前 HybridFlow 可使用 Megatron-LM 和 PyTorch FSDP 作为训练后端,同时使用 vLLM 作为自回归生成后端,支持用户使用其他框架的训练和推理脚本进行自定义扩展。
总结:封装单模型分布式计算
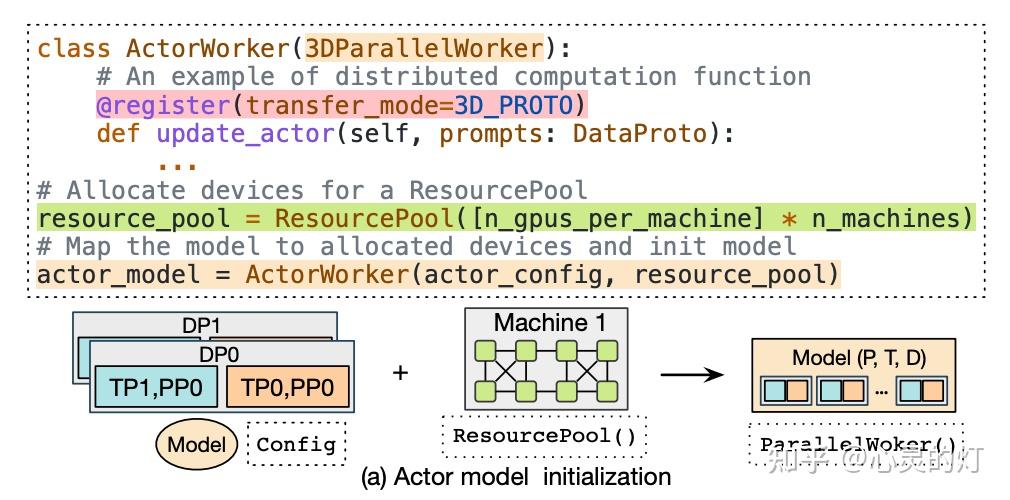
- 灵活的模型部署
HybridFlow 提供了资源池(ResourcePool)概念,可以将一组 GPU 资源虚拟化,并为每个模型分配计算资源。不同的资源池实例可以对应不同设备集合,支持不同模型在同一组或不同组 GPU 上部署。这种灵活的模型部署方式,满足了不同算法、模型和硬件环境下的资源和性能需求。
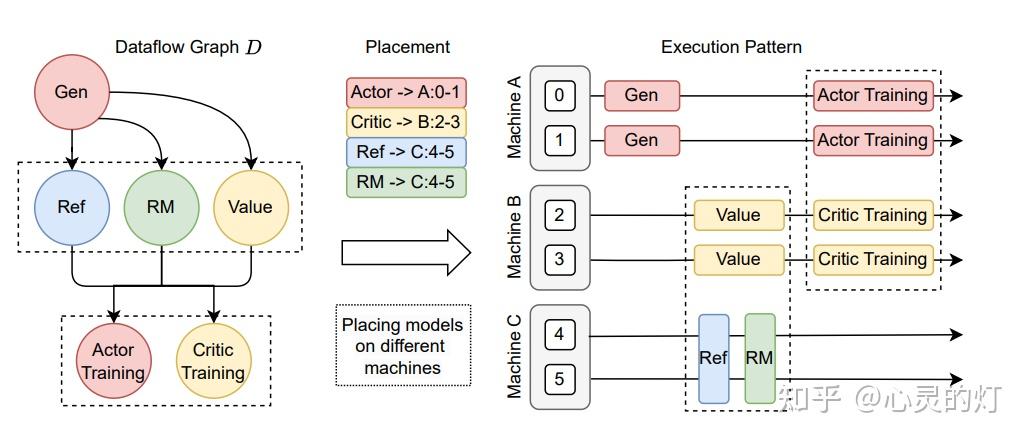
- 统一模型间的数据切分
在大模型 RL 计算流程中,不同模型之间的数据传输涉及复杂的多对多广播和数据重分片。
为解决该问题,HybridFlow 设计了一套通用数据传输协议(Transfer Protocol),包括收集(collect)和分发(distribute)两个部分。
通过在模型类的操作上注册相应的传输协议, 比如:@register(transfer_mode=3D_PROTO), HybridFlow 可以在控制器层(Single-Controller)统一管理数据的收集和分发,实现模型间数据的自动重分片,支持不同并行度下的模型通信。
HybridFlow 框架已经支持多种数据传输协议,涵盖大部分数据重切分场景。同时,用户可灵活地自定义收集(collect)和分发(distribute)函数,将其扩展到更复杂的数据传输场景。
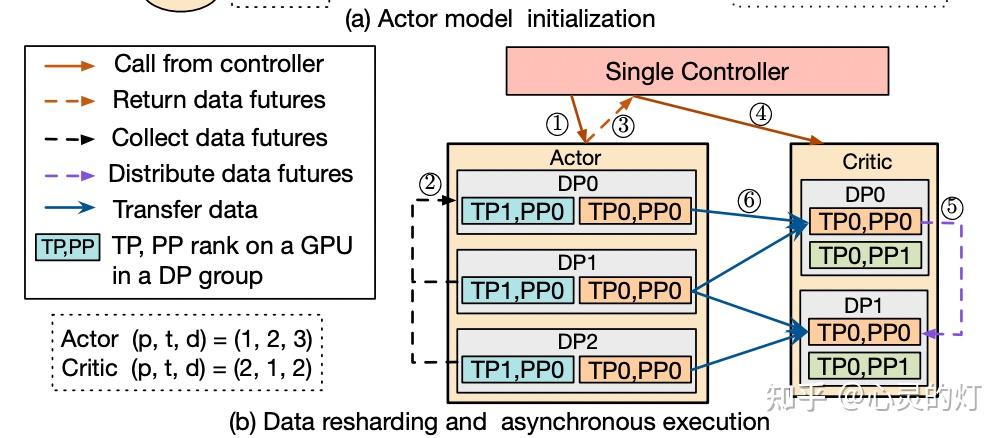
总结:Single-Controller 统一管理数据的收集和分发,实现模型间数据的自动重分片,支持不同并行度下的模型通信。
- 支持异步 RL 控制流
在 HybridFlow 中,控制流部分采用 单控制器架构 ,可灵活实现异步 RL 控制流。
当模型部署在 不同设备集合上时,不同模型计算可并行执行 ,这提高了系统的并行度和效率。对于部署在同一组设备上的模型,HybridFlow 通过调度机制实现了顺序执行,避免资源争夺和冲突。
总结:就是部署在不同的GPU上,不同模型计算可并行执行。
-
少量代码灵活实现各种 RL 控制流算法
得益于混合编程模型的设计,HybridFlow 可以方便地实现各种 RLHF 算法,如 PPO 、ReMax 、Safe-RLHF 、GRPO 等。用户只需调用 模型类的 API 接口 , 按算法逻辑编写控制流代码 ,无需关心底层的分布式计算和数据传输细节。
例如,实现 PPO 算法只需少量代码,通过调用 actor.generate_sequences 、 critic.compute_values 等函数即可完成。同时,用户只需要修改少量代码即可迁移到 Safe-RLHF 、ReMax 以及 GRPO 算法。

4. 系统设计之二:3D-HybridEngine (训练推理混合技术)降低通信内存开销
在 Online RL 算法中,Actor 模型需要在训练和生成(Rollout)阶段之间频繁切换,且两个阶段可能采用不同并行策略。
具体而言,训练阶段,需要存储梯度和优化器状态,模型并行度(Model Parallel Size, MP)可能相应增高,而生成阶段,模型无需存储梯度和优化器状态,MP 和数据并行度(Data Parallel Size, DP)可能较小。因此,在两个阶段之间,模型参数需要重新分片和分配,依赖传统通信组构建方法会带来额外通信和内存开销。
此外,为了在新的并行度配置下使用模型参数,通常需要在所有 GPU 之间进行全聚合(All-Gather)操作,带来了巨大的通信开销,增加了过渡时间。
为解决这个问题,HybridFlow 设计了 3D-HybridEngine ,提升了训练和生成过程效率。
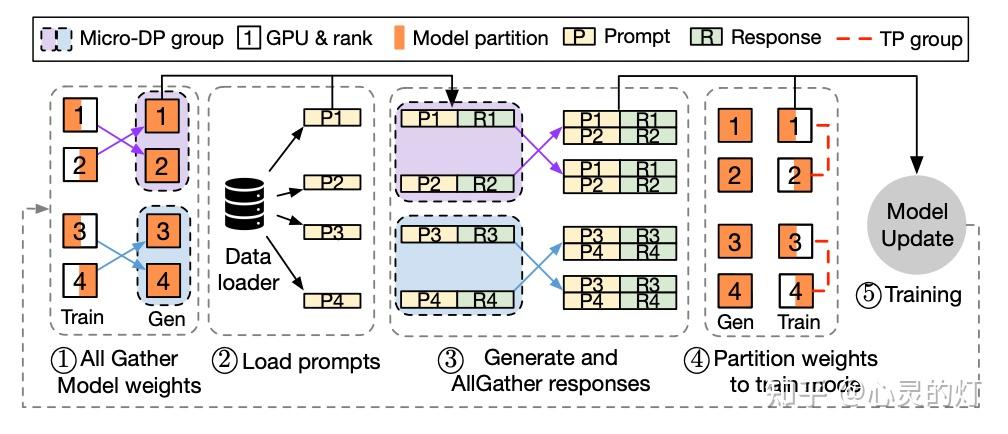
3D-HybridEngine 通过优化并行分组方法,实现了零冗余的模型参数重组,具体包括以下步骤:
- 定义不同的并行组
在训练和生成阶段,3D-HybridEngine 使用不同的三维并行配置,包括:流水线并行(PP)、张量并行(TP)和数据并行(DP)的大小。训练阶段的并行配置为 - - 。在生成阶段,我们新增一个新的微数据并行组(Micro DP Group, ),用于处理 Actor 模型参数和数据的重组。生成阶段的并行配置为 - - - 。
- 重组模型参数过程
通过巧妙地重新定义生成阶段的并行分组,可以使每个 GPU 在生成阶段复用训练阶段已有的模型参数分片,避免在 GPU 内存中保存额外的模型参数,消除内存冗余。
- 减少通信开销
参数重组过程中,3D-HybridEngine 仅在每个微数据并行组(Micro DP Group)内进行 All-Gather 操作,而非所有 GPU 之间进行。这大大减少了通信量,降低过渡时间,提高了整体的训练效率。
总结:训练阶段,需要存储梯度和优化器状态,模型并行度(Model Parallel Size, MP)可能相应增高,而生成阶段,模型无需存储梯度和优化器状态,MP 和数据并行度(Data Parallel Size, DP)可能较小。因此,在两个阶段之间,模型 参数需要重新分片和分配,依赖传统通信组构建方法会带来额外通信和内存开销 。
解决方案是:定义不同的并行组,训练阶段的并行配置为 - - 。在生成阶段的并行配置为 - - - 。每个 GPU 在生成阶段 复用训练阶段已有的模型参数分片 ,避免在 GPU 内存中保存额外的模型参数,消除内存冗余。在参数重组的过程中,仅在微数据并行组(Micro DP Group)内进行 All-Gather 操作,减少通信量。
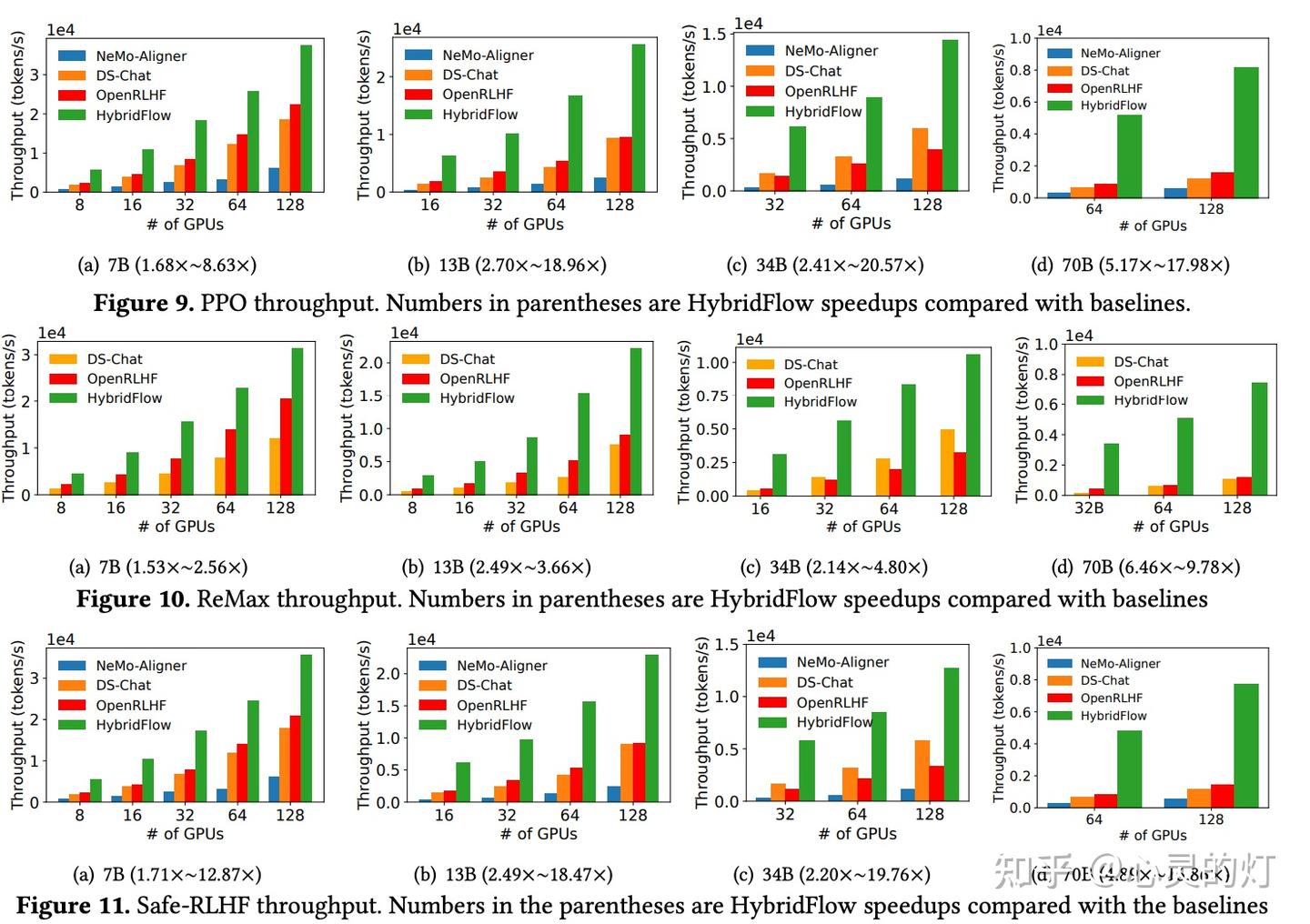
5. 实验结果:HybridFlow 提供灵活性的同时,加速了训练
团队在 16 台 A100 GPU 集群上,对 HybridFlow 和主流 RLHF 框架(DeepSpeed-Chat [6] v0.14.0、OpenRLHF v0.2.5 和 NeMo-Aligner v0.2.0)进行对比实验。实验涵盖了不同模型规模(7B、13B、34B、70B)的 LLM ,以及不同 RLHF 算法(PPO 、ReMax [10]、Safe-RLHF )。
所有实验中,Actor、Critic、参考策略 Reference Policy 和奖励模型 Reward Model 均采用相同规模模型。更多实验配置和测试细节请移步完整论文。
- 更高的端到端训练吞吐量
结果显示,HybridFlow 在各种模型规模和 RLHF 算法下,都显著优于其他框架,实现了更高训练吞吐量。
无论 PPO 、ReMax 还是 Safe-RLHF 算法,HybridFlow 在所有模型规模下平均训练吞吐量均大幅领先于其他框架,提升幅度在 1.5 倍至 20 倍之间。
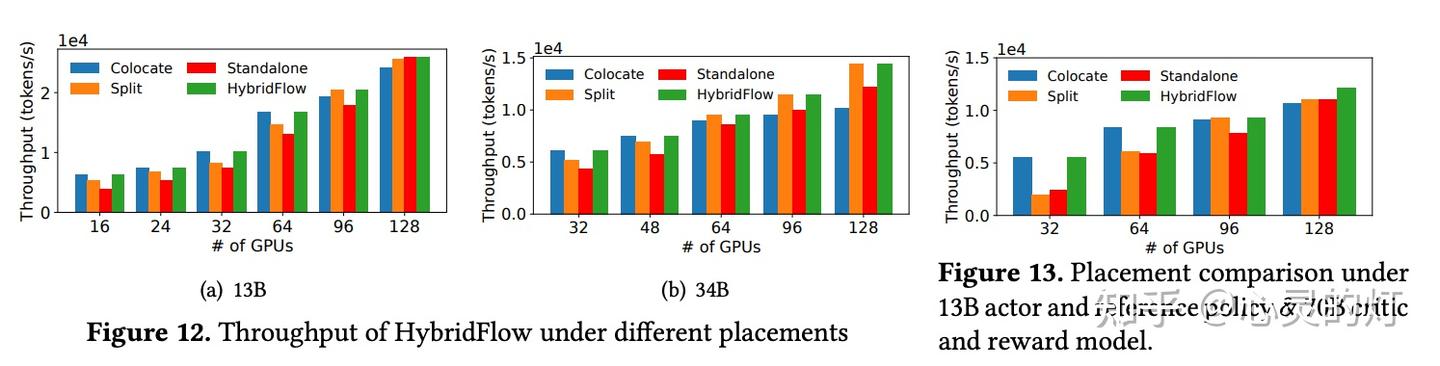
随 GPU 集群规模扩大,HybridFlow 吞吐量也获得良好扩展。这得益于其灵活的模型部署,充分利用硬件资源,实现高效并行计算。同时,HybridFlow 能够支持多种分布式并行框架(Megatron-LM 、FSDP 、vLLM ),满足不同模型规模的计算需求。
- HybridEngine 有效减少开销
分析 Actor 模型在训练和生成阶段的过渡时间,团队发现,HybridFlow 的 3D-HybridEngine 的 零冗余模型参数重组技术 ,有效减少了模型参数在两个阶段之间的重分片和通信开销。
相比其他框架,过渡时间减少了 55.2% ,在 70B 模型上过渡时间降低了 89.1% 。
值得一提的是,HybridFlow 同样适用于更广泛的 RL 训练场景,随着 o1 模型诞生,业内对 Reasoning 能力、RL 关注度也在提升,团队后续将围绕相关场景进行探索和实验。
后记:
veRL有两个创新点
1、一个是将控制流和计算流进行解耦,解耦的方式是:使用了分开的控制器,其中控制流是由单控制器(Single-Controller)管理,计算流是由多控制器(Multi-Controller)负责。
2、零容冗余模型参数技术(Zero redundancy model resharding,节省内存和减少通信)
做法是在训练和推理阶段定义不同的并行组,然后在生成阶段 复用训练阶段已有的模型参数分片 (避免在 GPU 内存中保存额外的模型参数,消除内存冗余),然后在参数重组的过程中,仅在微数据并行组内进行All-Gather 操作,减少通信。
发布于 2025-05-12 17:50・北京强化学习 (Reinforcement Learning)大模型训练框架